Seguimiento de la calidad del aire con WAQI y software libre
-
 yayitazale
yayitazale
- July 17, 2022

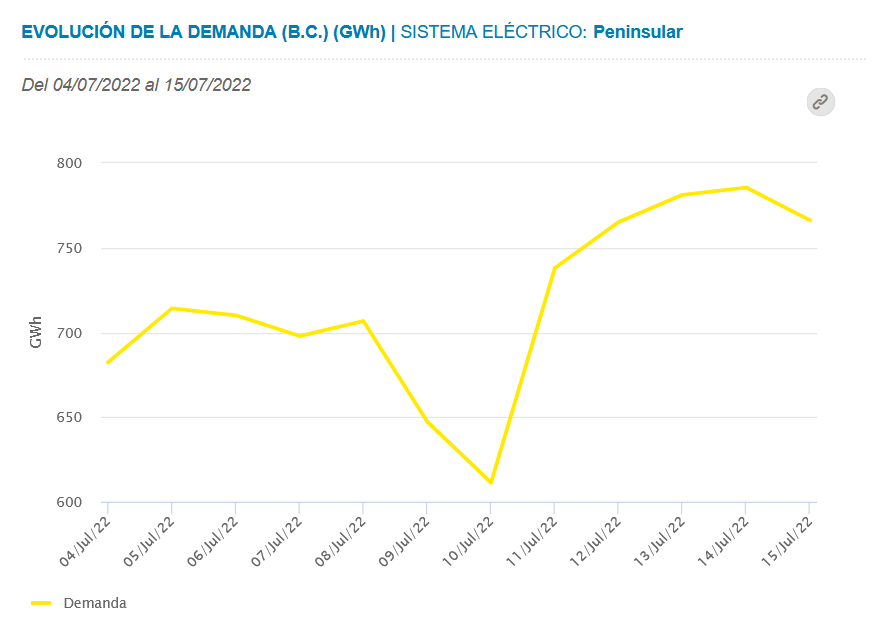
Con esta ola de calor que estamos viviendo en toda Europa, la calidad del aire que respiramos está empeorando de forma notable. En este artículo os voy a explicar cómo podemos monitorizar la calidad de aire de nuestro entorno sin una sola línea de código, utilizando software libre y la plataforma WAQI (World’s Air Pollution: Real-time Air Quality Index), una plataforma abierta que se nutre de los datos públicos de millones de estaciones de medición de calidad del aire por todo el planeta, y software libre (NodeRed, InfluxDB y Grafana).
En mi caso, el ejemplo se centra en la estaciones de Euskadi, ya que es donde vivo yo, pero es aplicable a cualquier región y país del mundo.
(Foto de portada Peter Werkman en Unsplash)
TOC
- Calima
- Requisitos
- Base de datos TimeSeries en InfluxDB
- Datos de calidad del aire desde WAQI con NodeRed
- Dashboarding en Grafana
Calima
Lo primero que vamos a entender antes de empezar a instalar y configurar servicios es por qué ocurre la calima:
- Una masa de aire caliente en diferentes capas atmosféricas procedente normalmente de los desiertos africanos se desplaza hacia el norte llegando a Europa. En esta ocasión esto ocurre debido a la presencia de un anticiclón potente a la altura de las Azores que rota en sentido contrario a las agujas del reloj, unido a una borrasca en el norte que vuelve a empujar el aire caliente hacia el centro de Europa donde tenemos otro anticiclón absorbiendo esta masa de aire caliente.

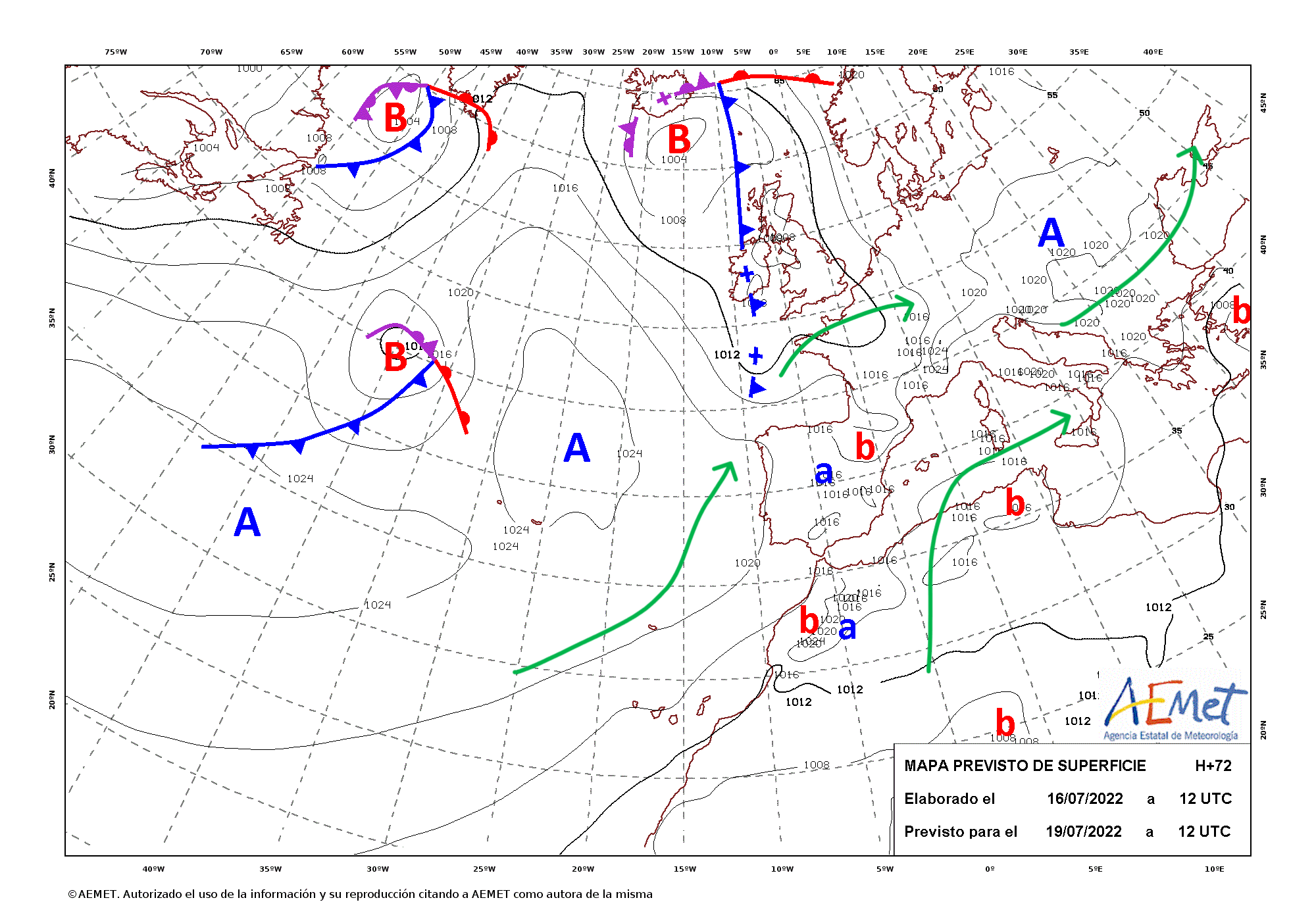
- Esta masa de aire producida por el trío anticiclón/borrasca/anticiclón queda bloqueado por las corrientes de chorro polar y subtropical.
- La falta de circulación de aire atrapa en este bucle los gases de efecto invernadero creando así un efecto invernadero (efectivamente, es el efecto que generan)
- El calor absorbido por la capa superficial de la tierra por la luz visible del sol que es capaz de atravesar esta capa de gases en su dirección a la tierra es devuelta hacia la troposfera en forma de radiación térmica.
- Está longitud de onda no visible no es capaz de atravesar la capa de gases, rebotando y volviendo de nuevo a la superficie de la tierra y haciendo que la temperatura aumente aún más.
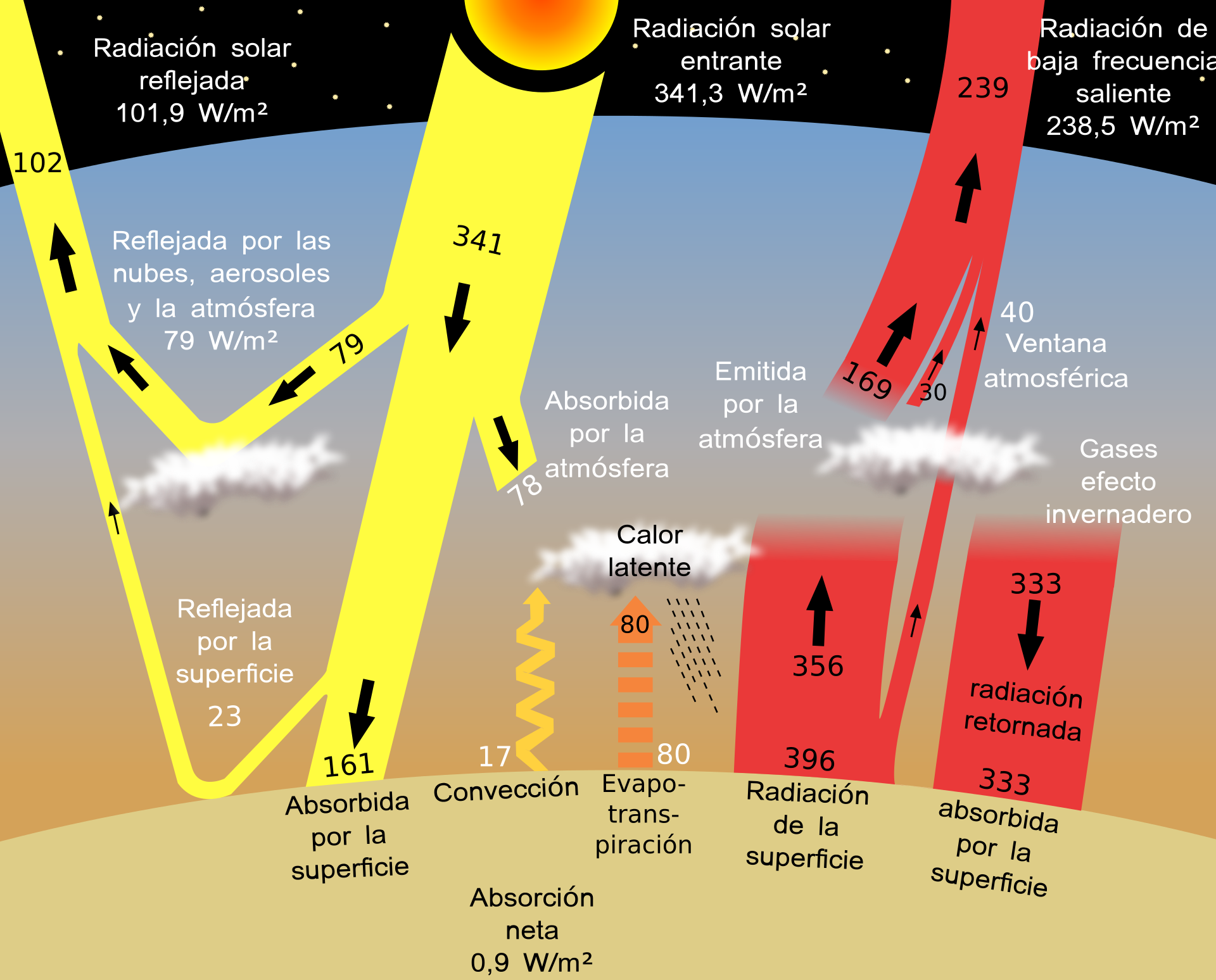
- Además a esto debemos sumar que por las noches ocurre una inversión térmica, dado que la capa superficial de la tierra se enfría más rápido que la parte alta de la troposfera y esto hace que la contaminación emitida durante el día no pueda disiparse a la estratosfera de noche ya que queda atrapada por debajo de una capa de aire más caliente y por tanto menos densa que la de abajo.
- A todo esto hay que sumar que con este aumento de temperatura le sigue un riesgo extremo de incendios forestales que de ocurrir, aumentan aún más la cantidad de gases de efecto invernadero que se acumulan en la capa alta de la troposfera.
- Finalmente, el aumento de las temperaturas trae además un aumento de l consumo eléctrico por el uso de los aires acondicionados, lo cual suele generar un aumento de las emisiones por quema de gas y otro combustibles fósiles para abastecer la demanda electrica.
Requisitos
Ahora que hemos entendido cómo se genera esta situación vamos a ver los requisitos mínimos para seguir este post.
Lo primero es contar con un servidor doméstico e idealmente el sistema operativo Unraid. También podéis montar esto sobre una placa tipo Raspberry PI pero no quiero extenderme demasiado por lo que no voy a entrar a explicar los detalles de cómo instalar y utilizar Docker, ni los servicios que vamos a utilizar sobre RPI. En Unraid tenemos todo preparado, por lo que los pasos a seguir son mucho más sencillos.
En segundo lugar necesitaremos tener instalado el stack de software libre con el que podemos monitorizar prácticamente lo que se nos ocurra. Como ya he explicado esto en anteriores posts, os dejo aquí en enlace para que aprendáis a instalar y configurar los tres elementos que necesitamos (como decía también puedes instalar esto por tu cuenta en una RPI):
Base de datos TimeSeries en InfluxDB
Para este proyecto vamos a necesitar crear dos bases de datos en InfluxDB, uno para el almacenamiento de los datos en bruto (horarios) que obtendremos de WAQI y otro para el almacenamiento de datos agregados (diarios). De esta manera podremos realizar una visualización detallada de los últimos 15 días y al mismo tiempo una visualización de tendencias a más largo plazo de forma dinámica y sin perder apenas rendimiento.
Para ello entramos a nuestro chronograf y vamos a Buckets:
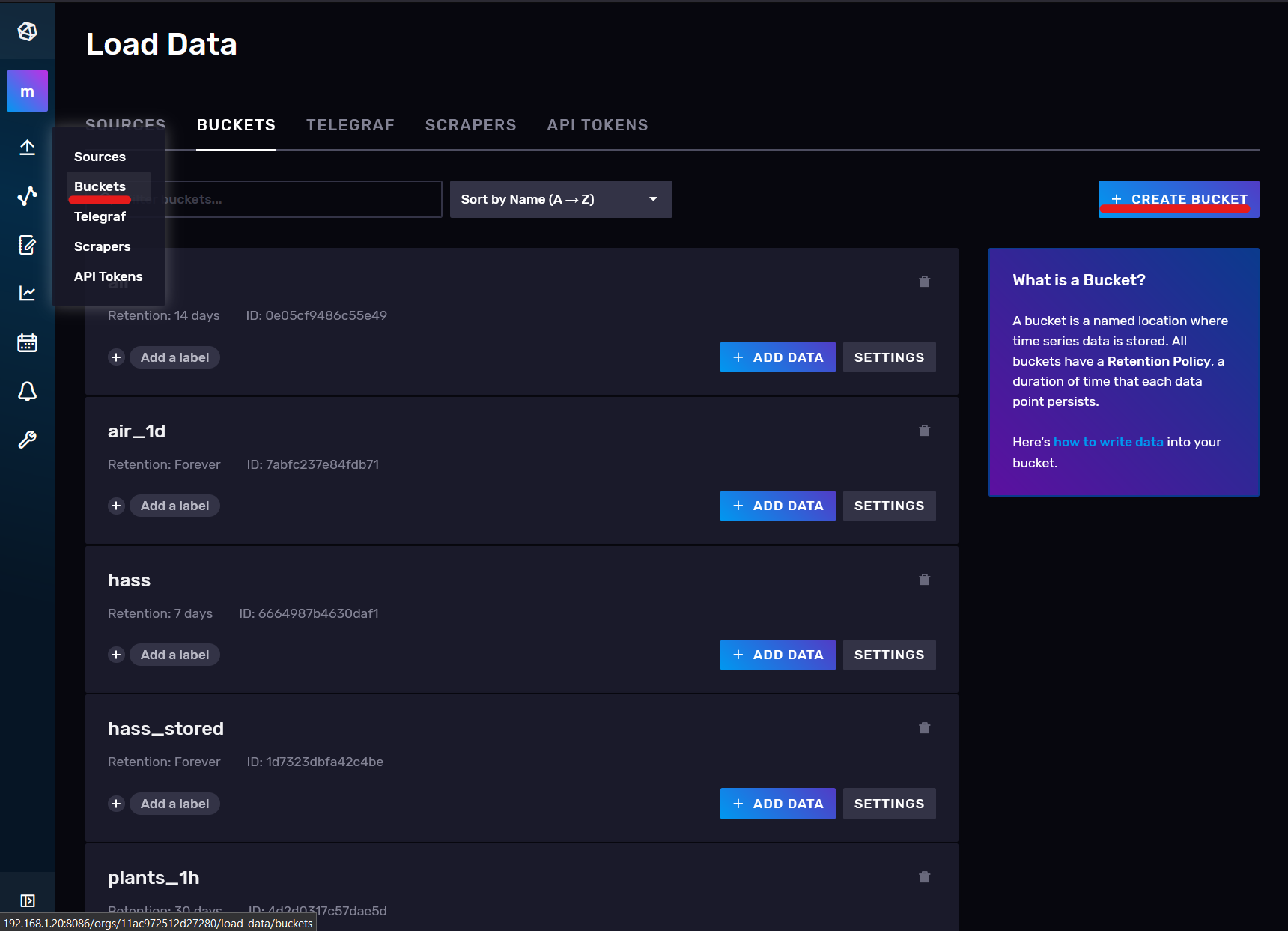
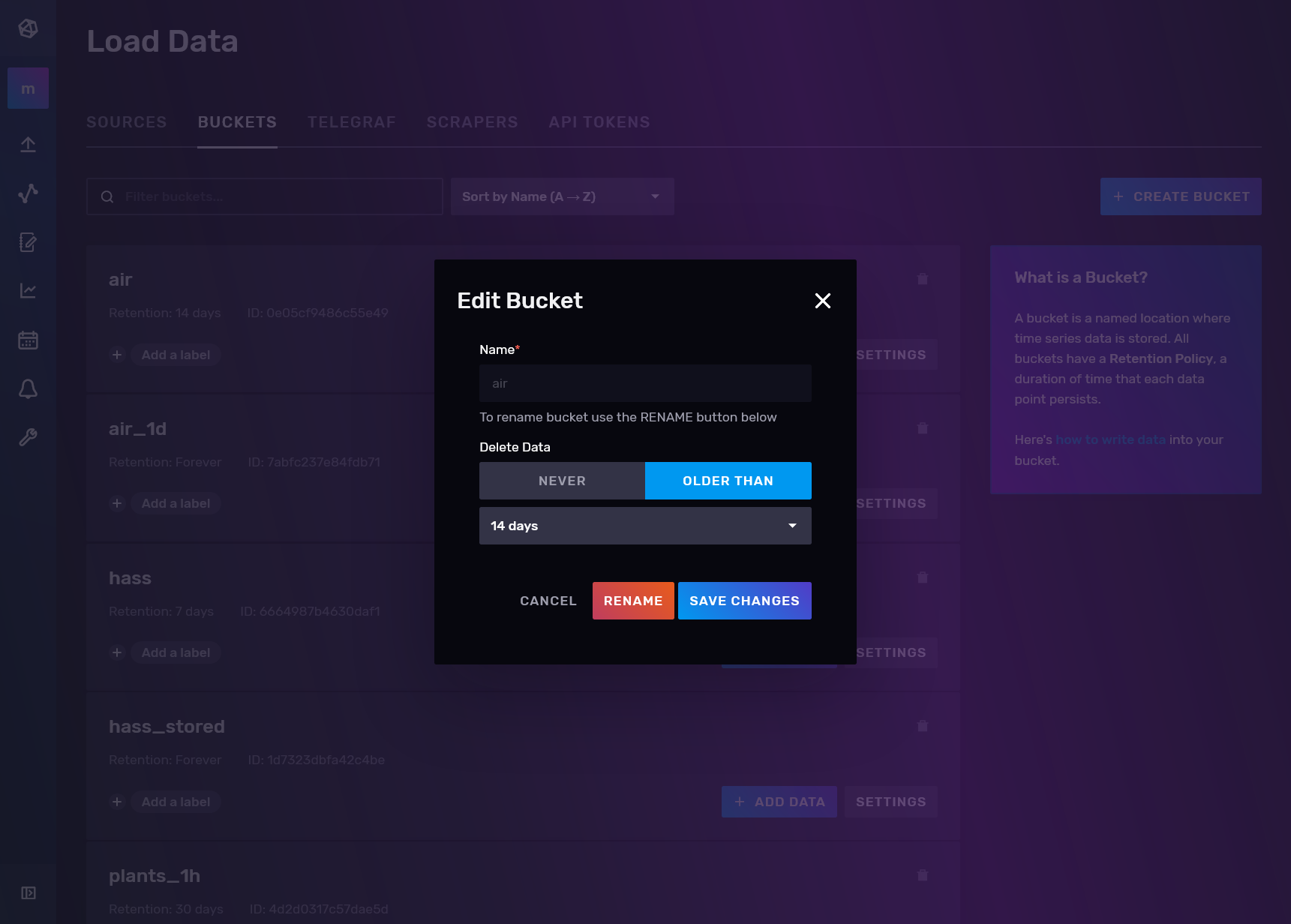
Aquí creamos uno llamado Air con la siguiente configuración, con la que los datos de más de 14 días serán eliminados automaticamente:
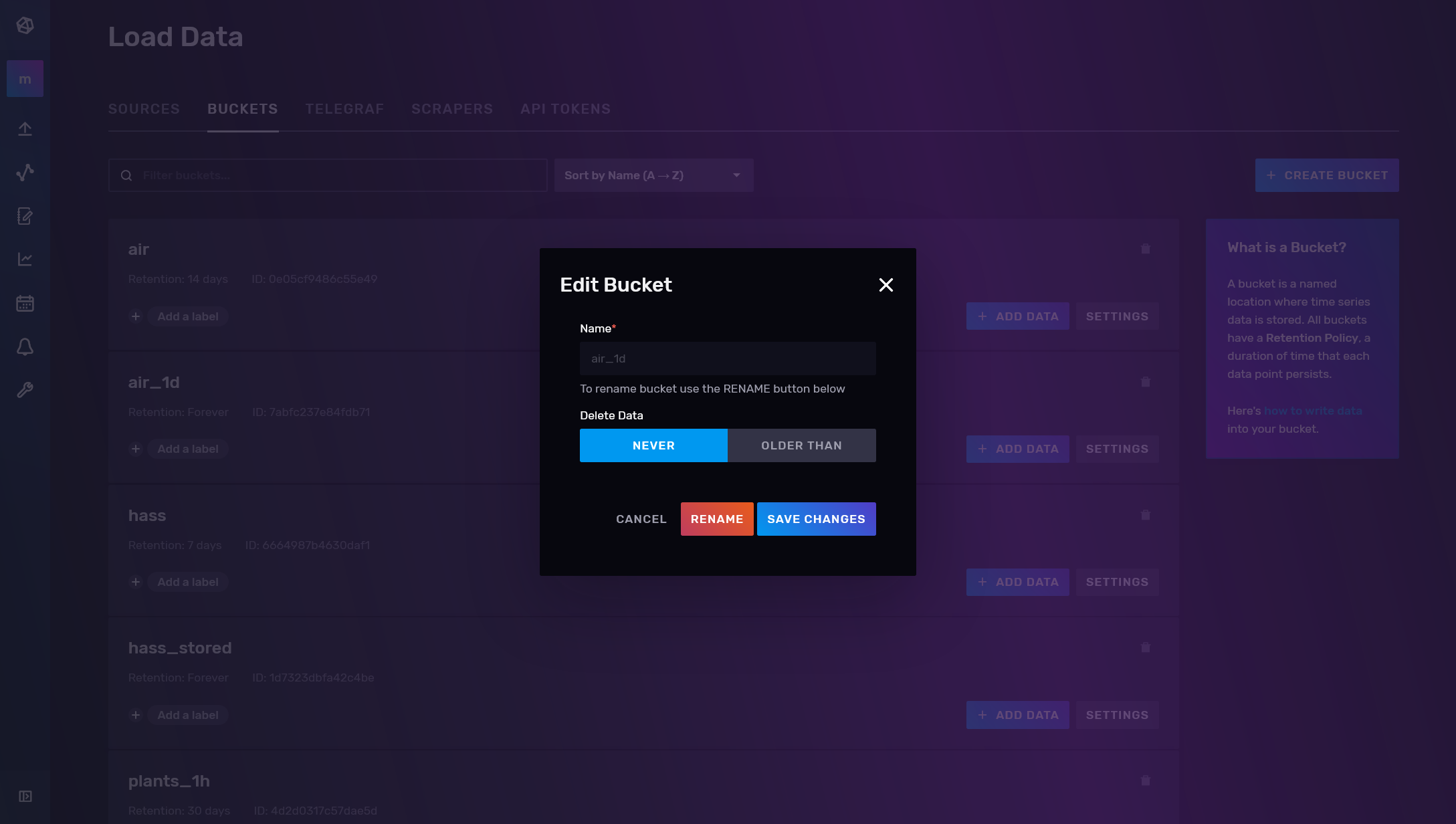
Y otro con la una configuración diferente llamada Air_1d donde no tendremos restricción de almacenamiento por fecha:
Ahora vamos a crear un token de acceso para Node-Red:
Y lo anotamos en un bloc de notas para poder usarlo posteriormente.
Para terminar con la configuración de la base de datos, vamos a crear un proceso repetitivo donde cogeremos los datos de la base de datos Air que tendrán una resolución horaria, les bajaremos la resolución a un día y los almacenaremos en la base de datos Air_1d. Para ello vamos al icono del calendario y hacemos clic en create task:
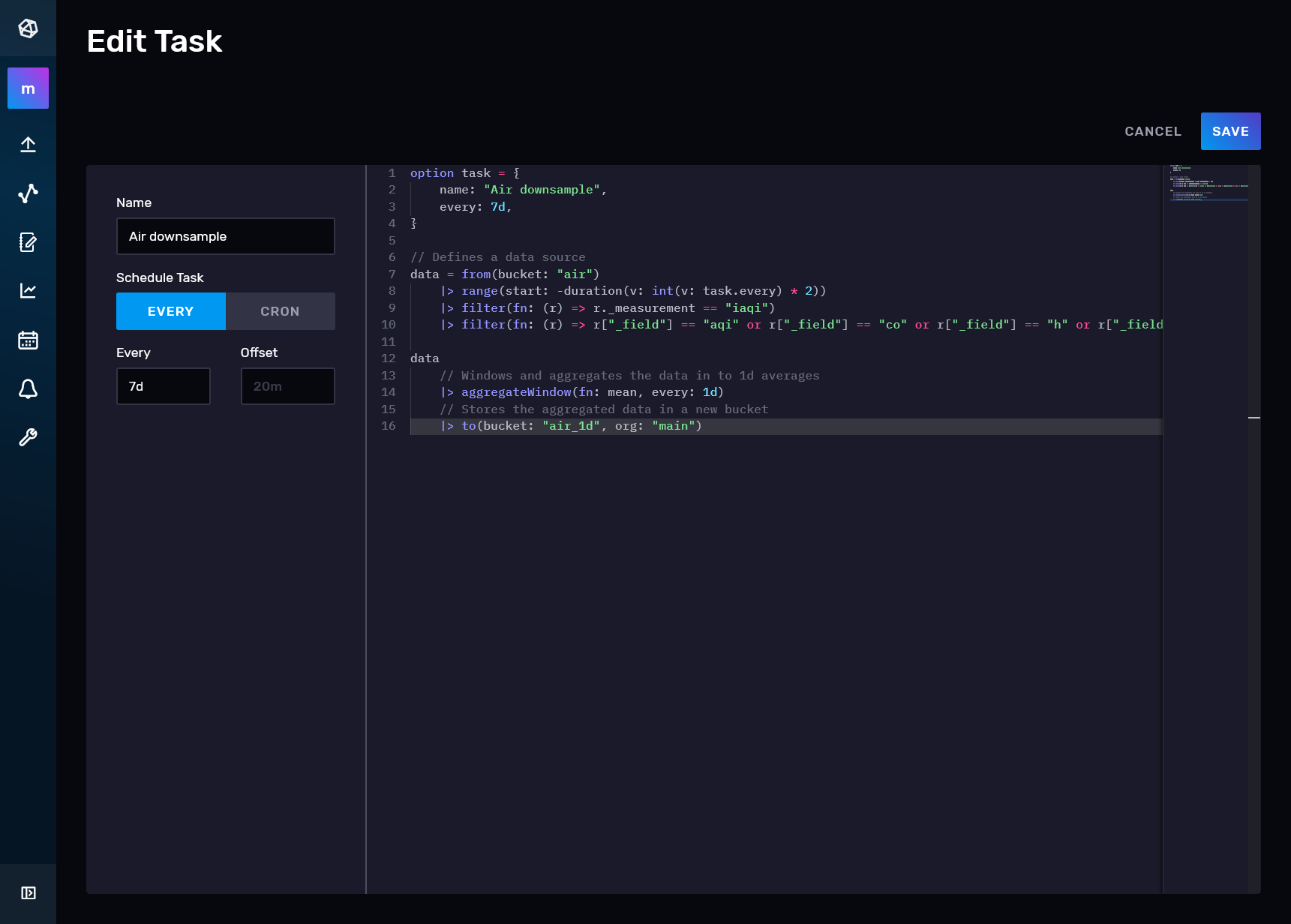
Le ponemos un nombre y metemos el siguiente código, que se ejecutará cada 7 días, cogerá los datos horarios de Air desde hace 15 días a hace 7 días, les aplicará una reducción de la medía diaria y los almacenará en Air_1d:
option task = {name: "Air downsample", every: 7d}
// Defines a data source
data =
from(bucket: "air")
|> range(start: -duration(v: int(v: task.every) * 2))
|> filter(fn: (r) => r._measurement == "iaqi")
|> filter(
fn: (r) =>
r["_field"] == "aqi" or r["_field"] == "co" or r["_field"] == "h" or r["_field"] == "lat" or r["_field"]
==
"lon" or r["_field"] == "no2" or r["_field"] == "o3" or r["_field"] == "p" or r["_field"] == "pm10"
or
r["_field"] == "pm25" or r["_field"] == "so2" or r["_field"] == "t" or r["_field"] == "w"
or
r["_field"] == "wg",
)
data
// Windows and aggregates the data in to 1d averages
|> aggregateWindow(fn: mean, every: 1d)
// Stores the aggregated data in a new bucket
|> to(bucket: "air_1d", org: "main")Guardamos y activamos la tarea:
Datos de calidad del aire desde WAQI con NodeRed
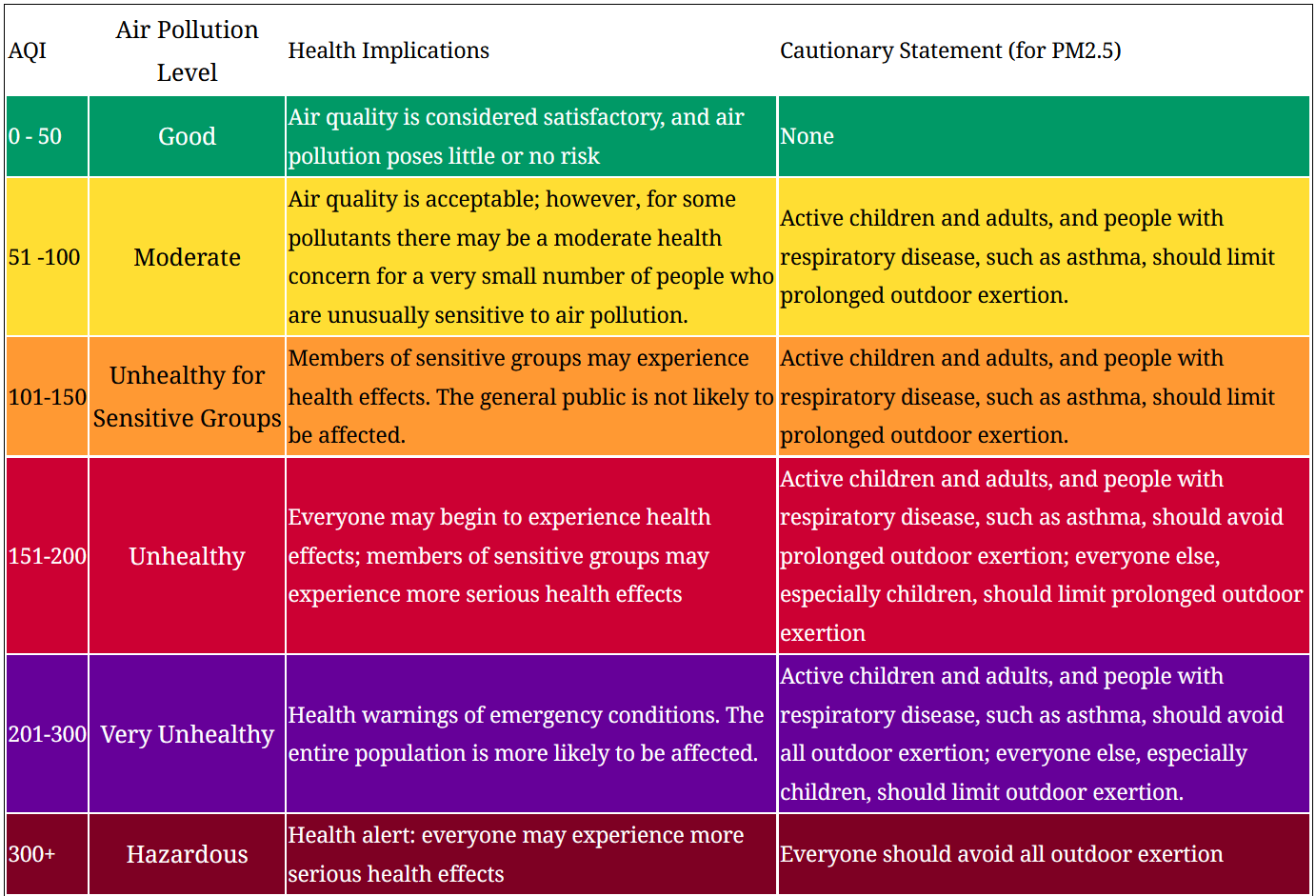
WAQI es un servicio que nace del proyecto Air Quality Index China que después de varios años monitorizando la calidad del aire del país asiático, se abrió al mundo. La calidad de aire de esta plataforma se basa en valores indexados de las diferentes estaciones de medición que puede haber en el mundo. Esto quiere decir que los valores medidos en bruto por los sensores pueden tener diferentes escalas y/o unidades de medida, por lo que se convierte la medición de cada estación a un valor numérico estandar sin unidad de medida:
En el caso de Euskadi, los datos de las estaciones de calidad de aire los obtienen desde la API publica de OpenData Euskadi, la plataforma de datos públicos y transparencia del Gobierno Vasco.
Esta plataforma integra datos de todos los medidores de calidad del aire instalador por el Gobierno Vasco por toda la geografía vasca de los que se ofrecen medias horarias y diarias. Podríamos utilizar directamente los datos de estos medidores pero la idea es que este artículo sea replicable por cualquiera, por lo que utilizaremos la API publica de WAQI en el cual podremos encontrar los datos de la mayoría de estaciones de calidad del aire de cualquier punto de país o del mundo.
(Por apuntar un detalle, estas estaciones son mantenidas y gestionadas por mi actual empresa, MSI Grupo, el cual recolecta los datos de forma automática y los envía al Gobierno Vasco en tiempo real)
Para poder capturar datos desde la API de WAQI tenemos toda la documentación publica, pero yo ya he creado unos flujos para ayudaros. Lo primero es crearnos una cuenta para generar un token de acceso a la API:
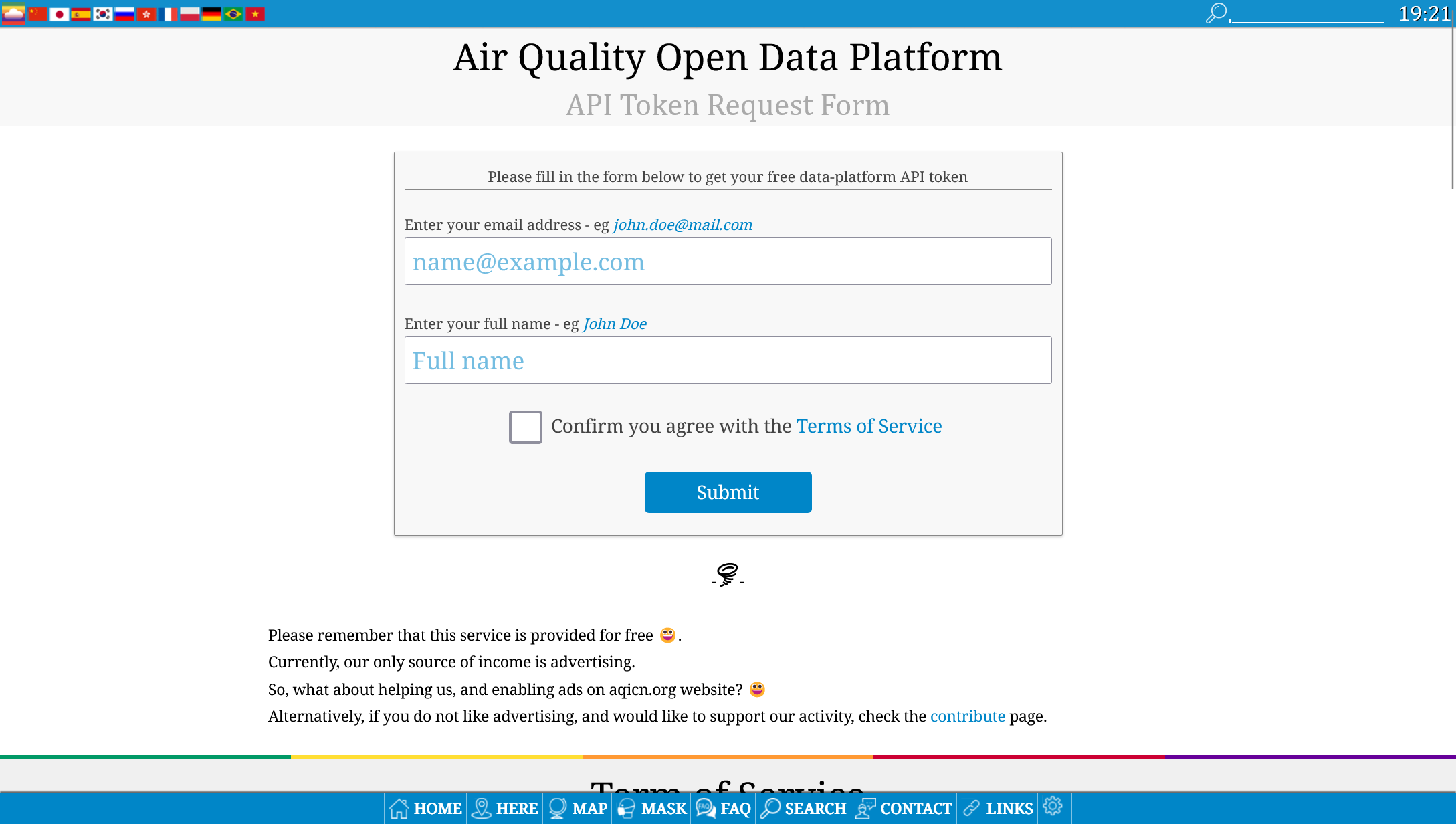
Copiamos el token en el bloc de notas para no perderlo y ahora debes descargarte los siguientes ficheros:
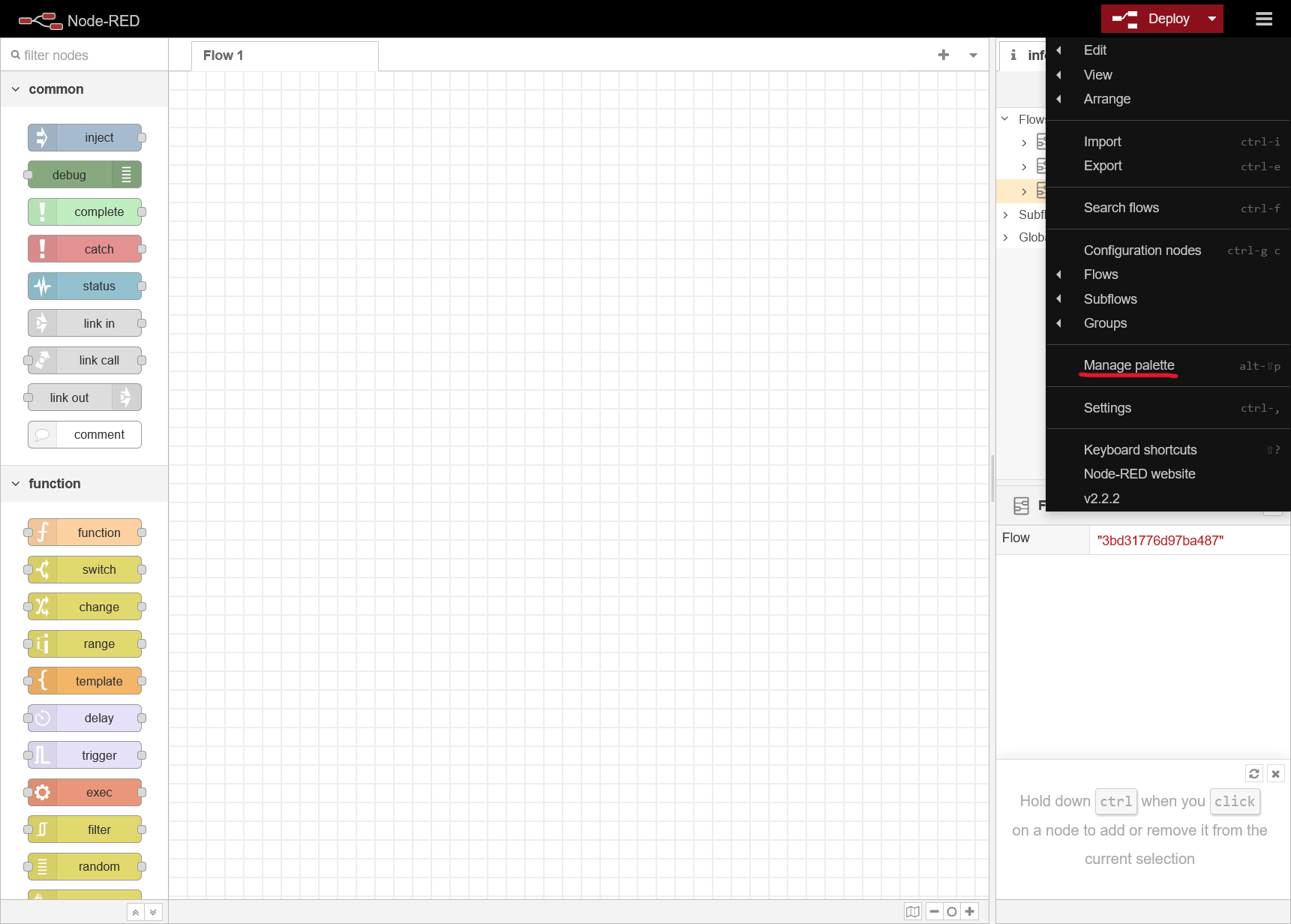
En NodeRed, vamos a instalar la liberia node-red-contrib-influxdb para poder subir los datos directamente a las bases de datos que hemos creado, para ello vamos al menu principal > Manage Pallete > Install y buscamos la librería e instalamos:
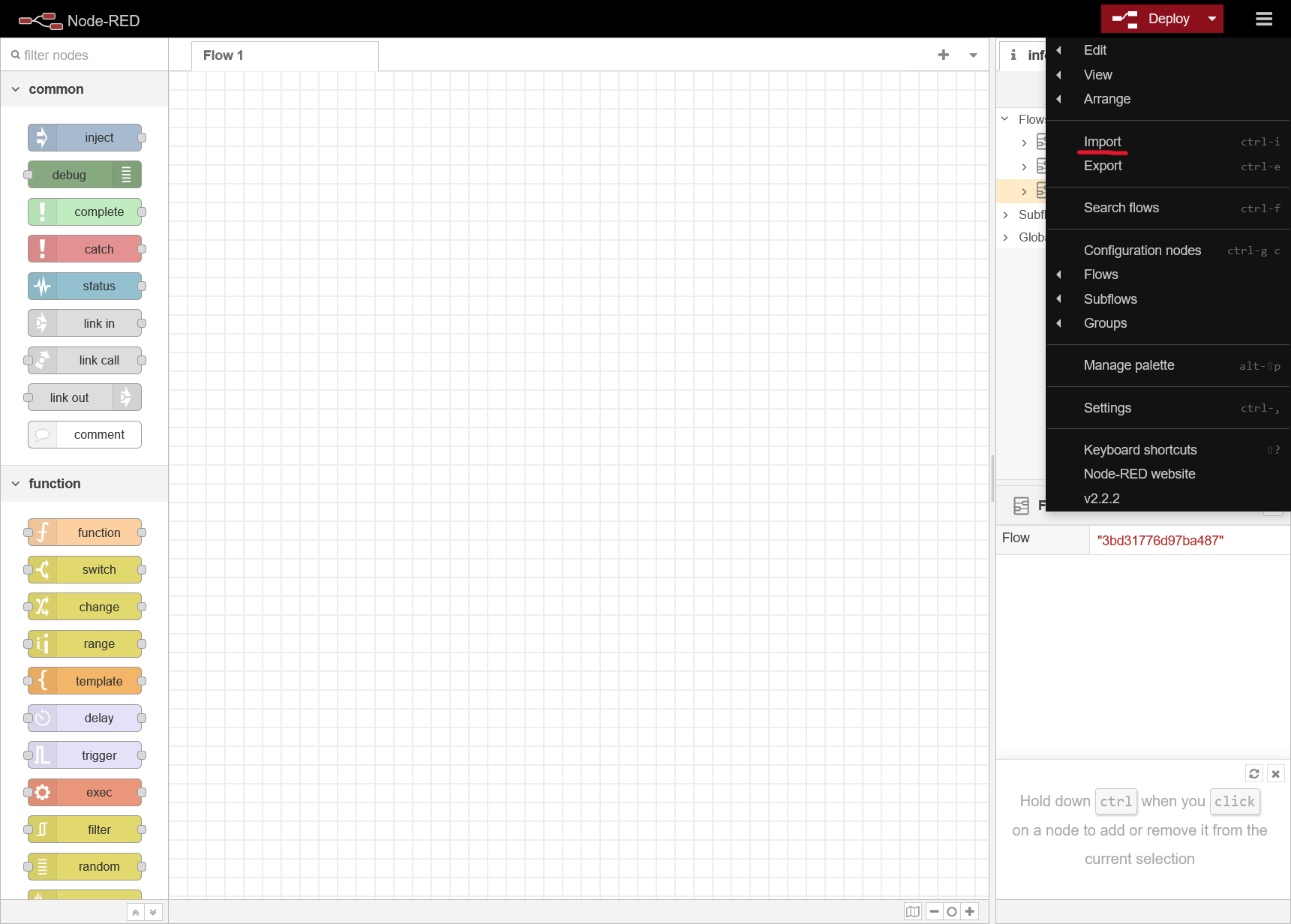
Cuando termine importamos el flow que he creado haciendo clic en el menú > Import > Select a file to import, os cargara el JSON y lo importais:
En este flow tendremos que modificar dos cosas:
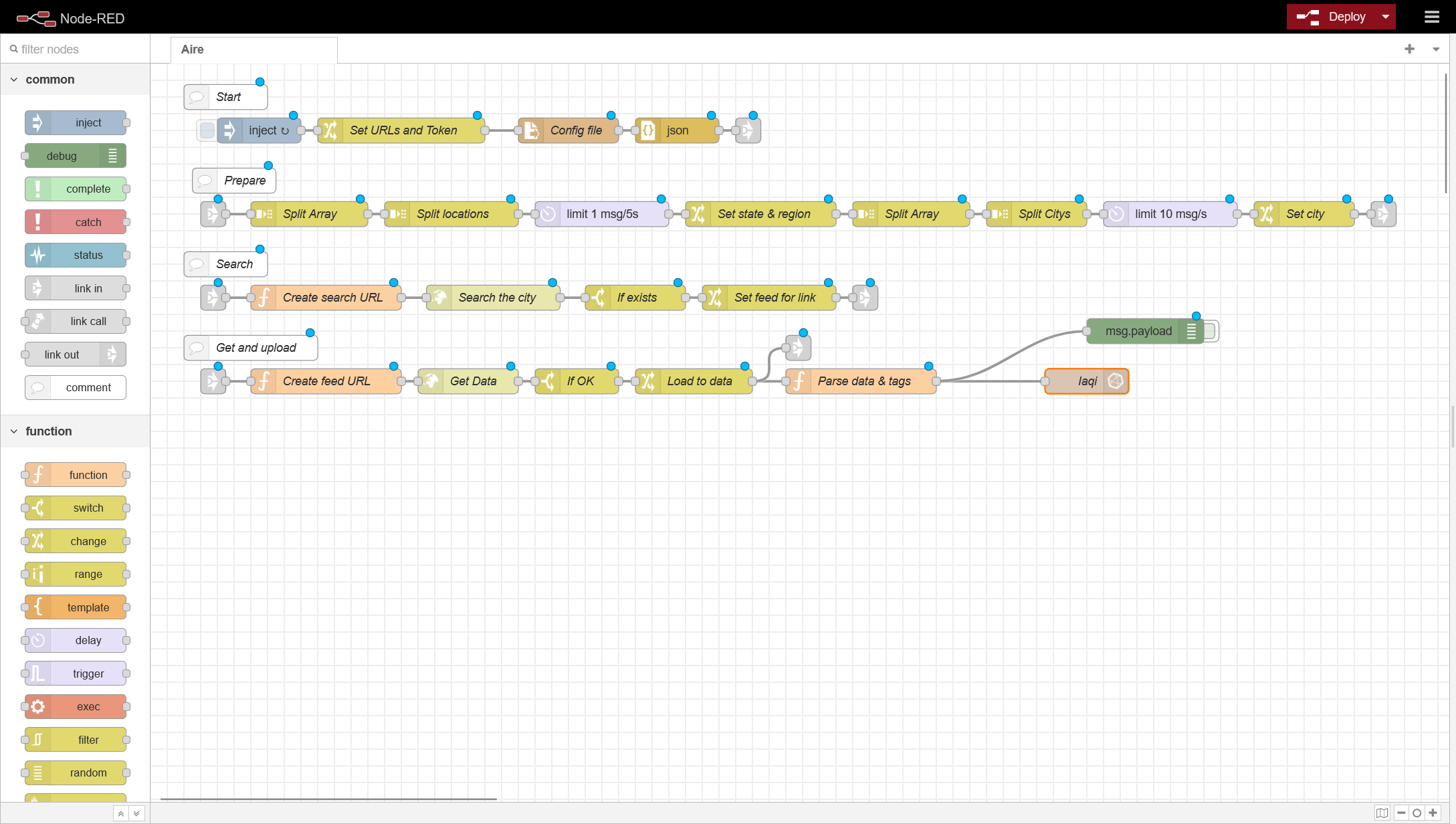
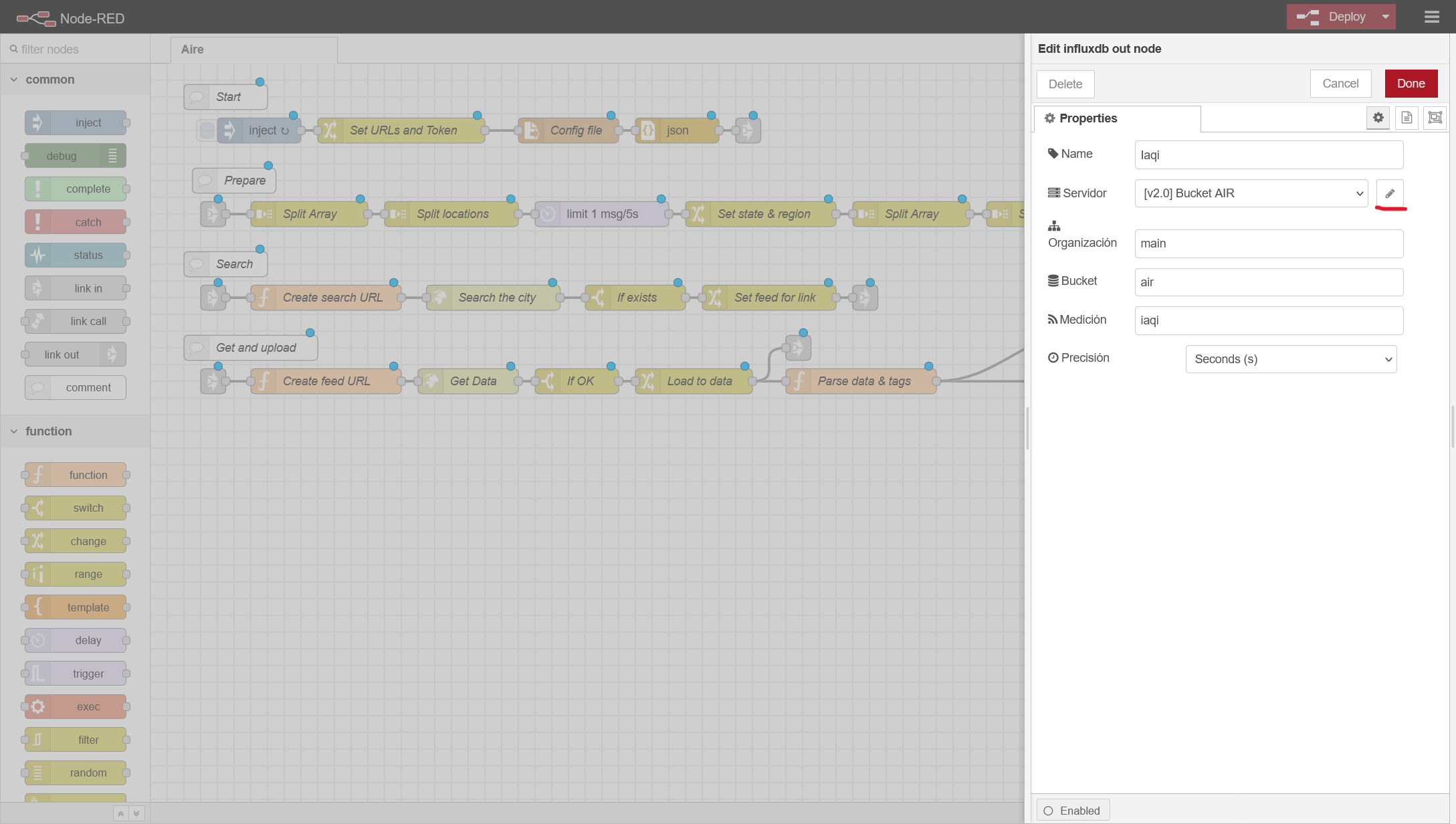
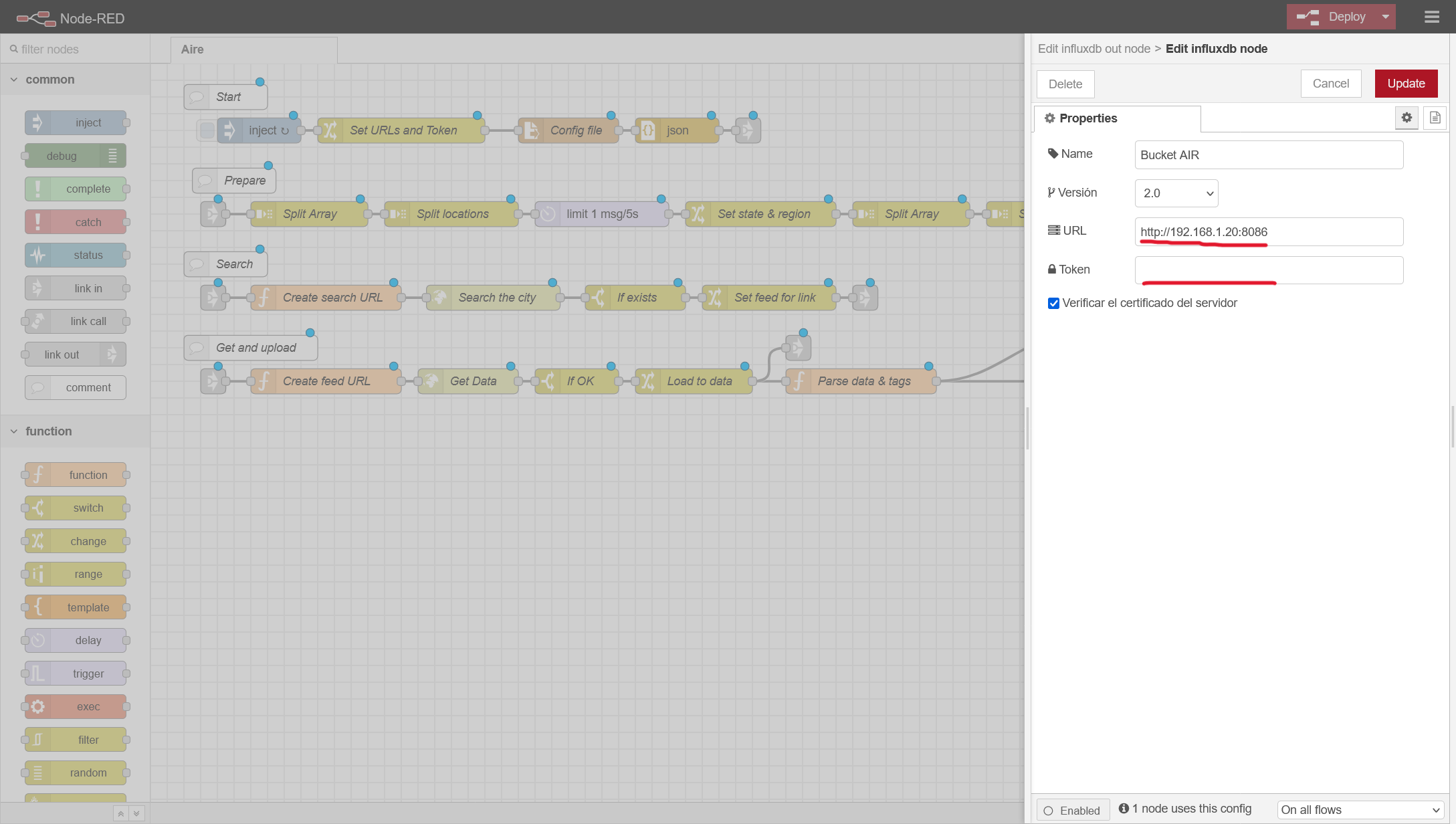
- La caja IAQI es el conector a influx, hacemos doble click y donde poner Air Bucket, hacemos clic en el lapiz y configuramos tanto la IP/Puerto de nuestro influx, y metemos el token que hemos generado:
- En la caja Set URLs and Token tendremos que meter el token que nos ha proporcionado WAQI al hacer la inscripción.
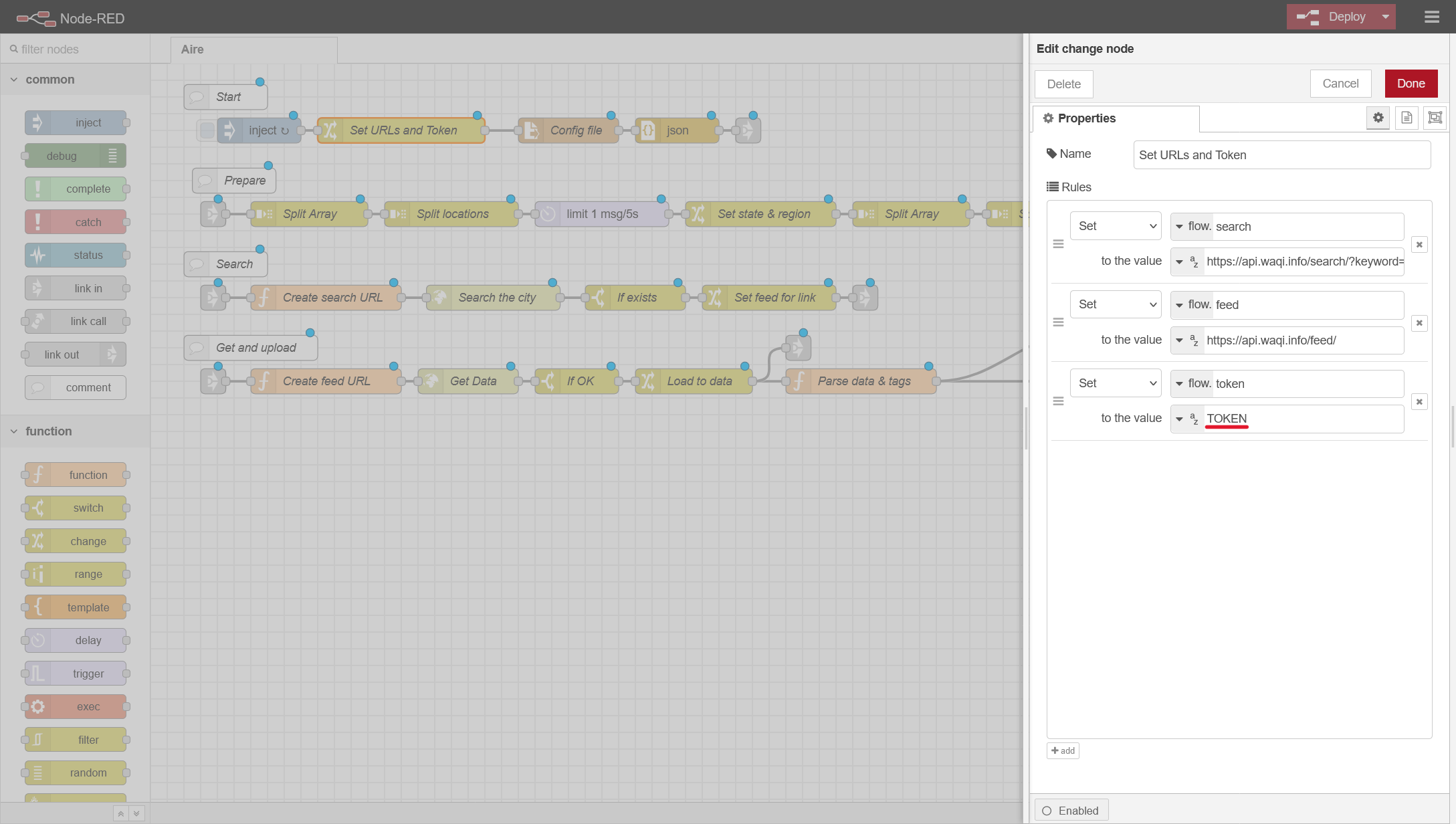
Ahora, antes de terminar, tendremos que configurar usando el fichero de configuración, las estaciones de las que queremos coger información.
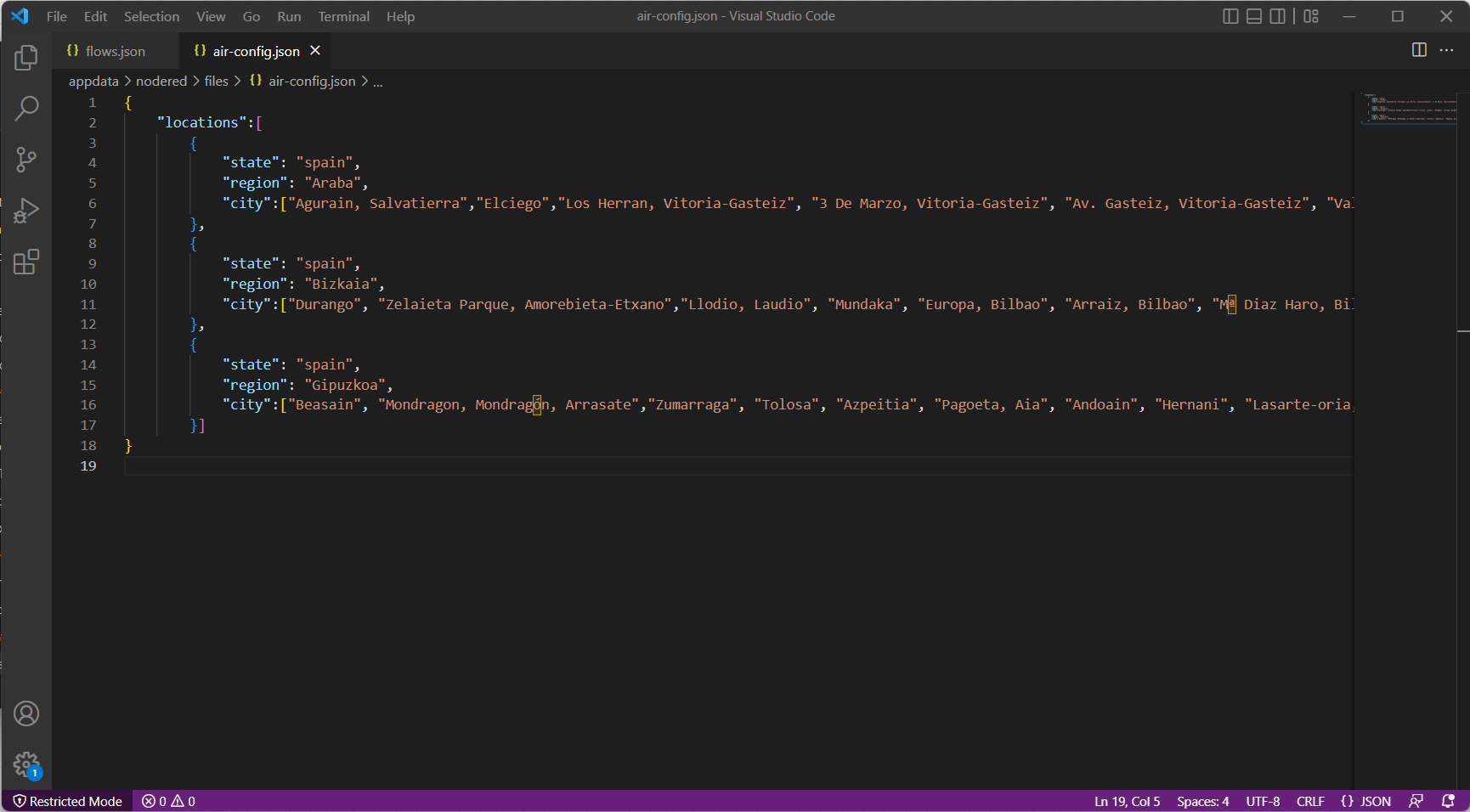
Si abres el fichero con un editor de código, podrás ver que se conforma de la siguiente manera: se añade un bloque por cada región, y dentro de cada bloque de región las estaciones concretas de las que queremos sacar datos. Los nombres de las regiones y las estaciones las utilizaremos después en Grafana como filtros dinámicos ya que serán las etiquetas de las variables que vamos a guardar en Influx. Para conocer los nombres de las estaciones lo más sencillo es utilizar el buscador web de WAQI y copiar y pegar el nombre directamente. Ojo, es importante que mantengas la estructura del JSON respetando las tabulaciones, corchetes, comas y llaves:
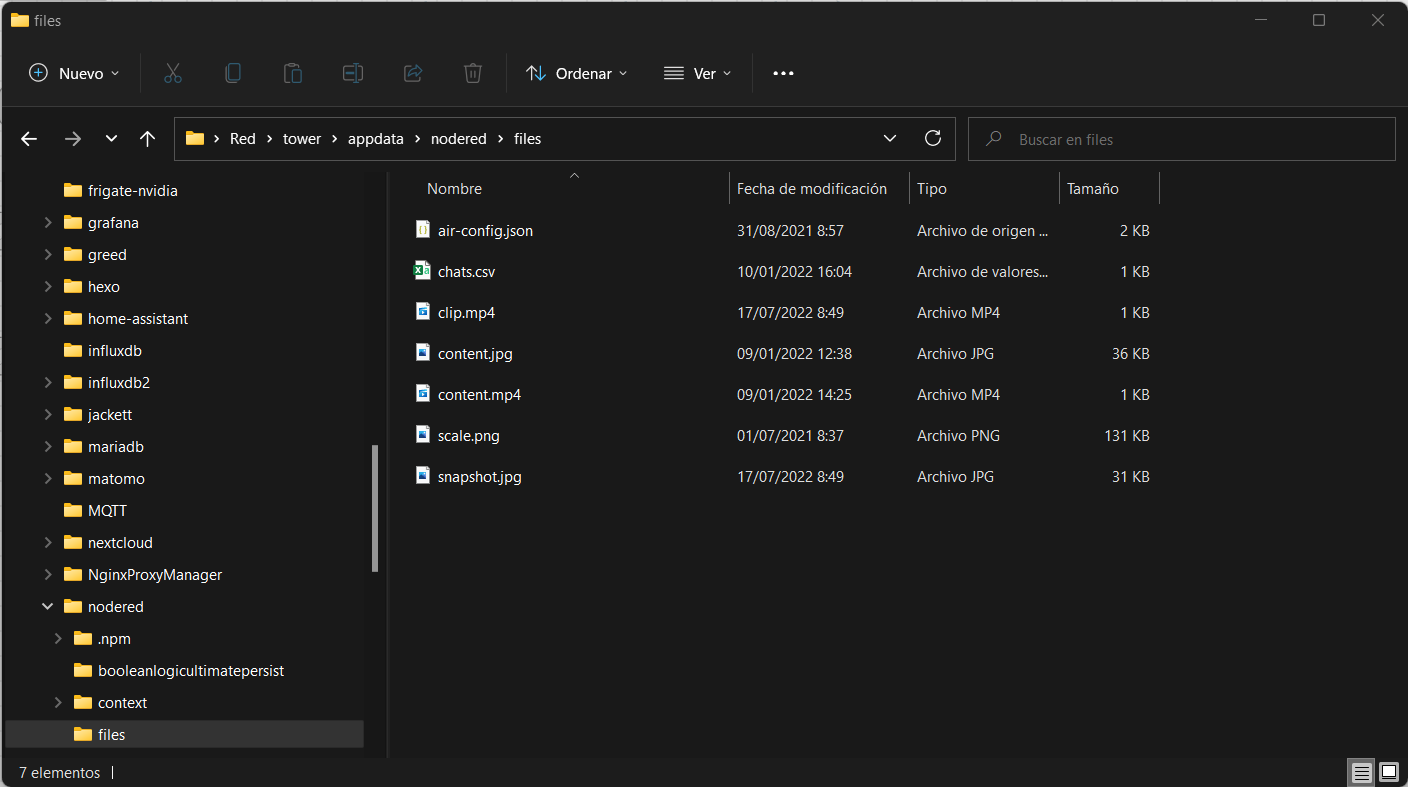
Una vez tengas tu fichero de configuración a tu gusto, debes dejarlo en la ruta \files del contenedor, para lo cual en el navegador de ficheros de tu ordenador vamos a IPUNRAID\appdata\nodered\files (o donde hayas mapeado tu carpeta de nodered):
Ahora volvemos a NodeRed y hacemos deploy, y ya tenemos nuestro sistema de captura de datos en marcha.
Dashboarding en Grafana
Para ayudarnos con la visualización vamos a utilizar Grafana, tal y como hicimos en el post sobre monitorización de servidores. De nuevo como aquella vez, tendremos que crear un token de acceso en lectura a las bases de datos Air y Air_1d en Chronograf para Grafana (ya te explicado como hacerlo).
Ahora vamos a crear un nuevo Dashboard en Grafana:
Y antes de dibujar nada, vamos a crear las variables sobre las etiquetas de región y estación que vamos a tener en influx. Para ellos vamos a configuración > Variables > Create Variable:
La primera variable que vamos a crear es el de región, al que yo he llamado Provincia, usando la siguiente query de exploración de etiquetas de InfluxDB:
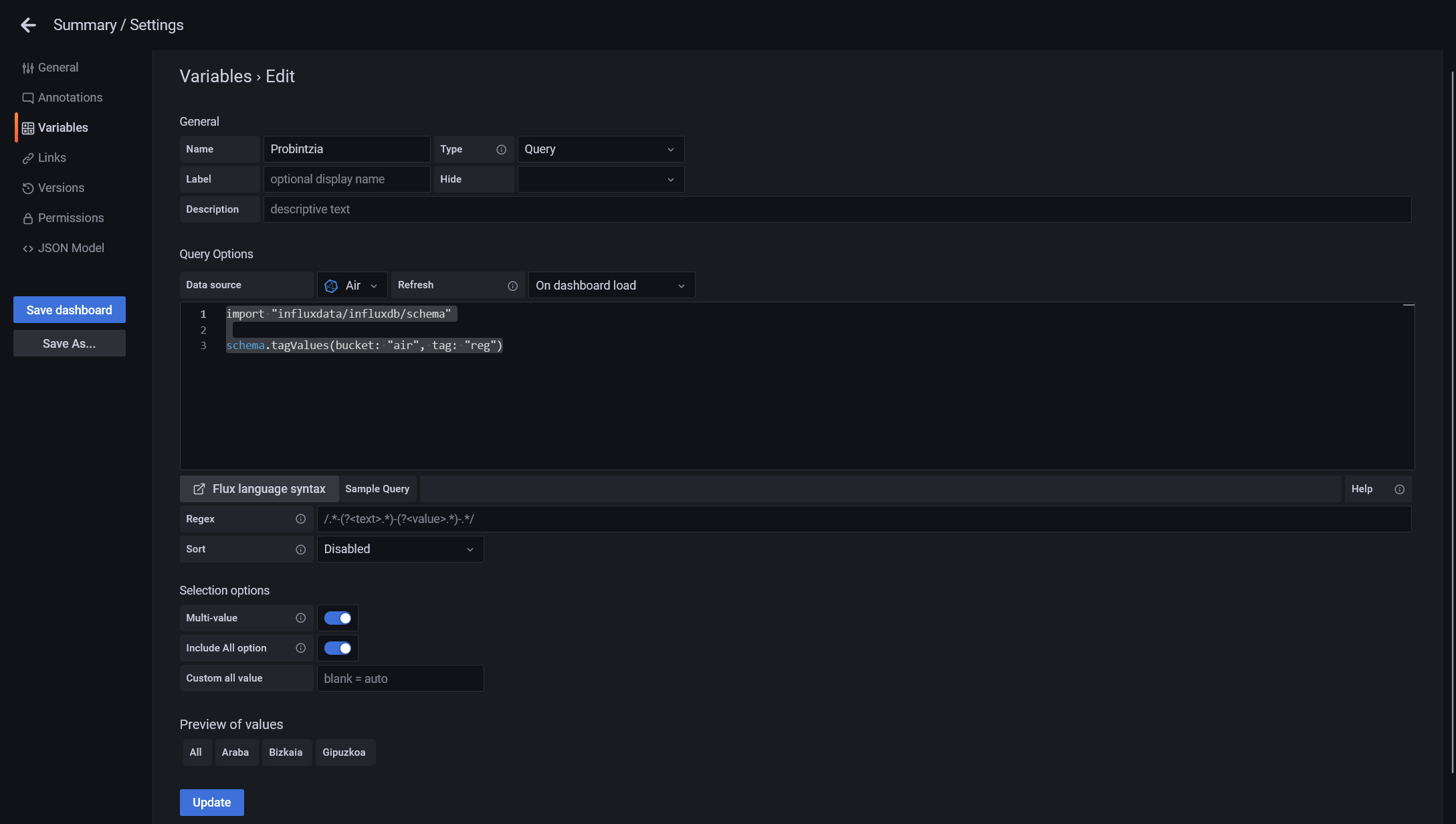
import "influxdata/influxdb/schema"
schema.tagValues(bucket: "air", tag: "reg")Guardamos y creamos otra, a la que yo he llamado Municipio:
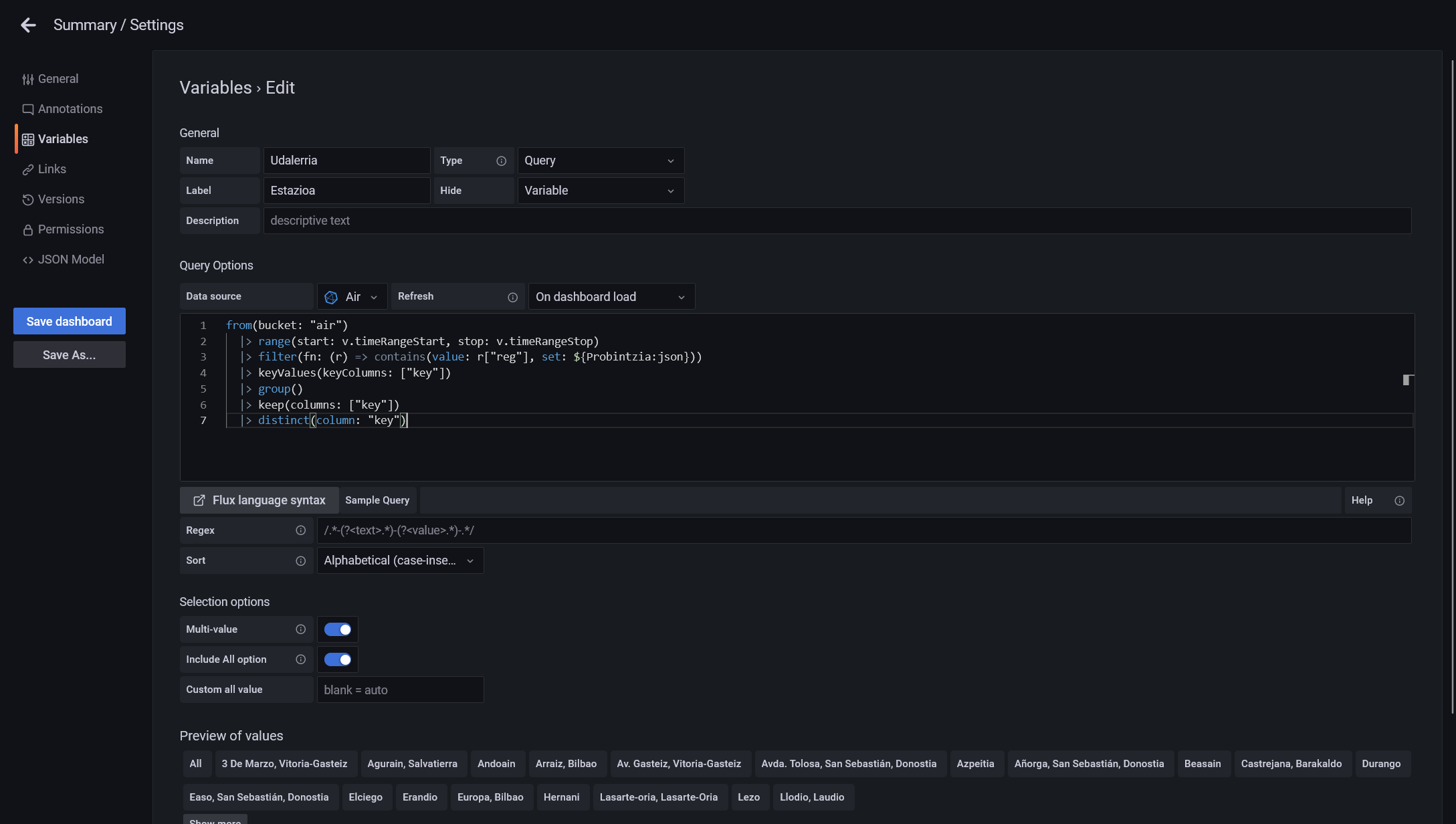
from(bucket: "air")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => contains(value: r["reg"], set: ${Probintzia:json}))
|> keyValues(keyColumns: ["key"])
|> group()
|> keep(columns: ["key"])
|> distinct(column: "key")Como puedes observar en el código de esta query, vamos a prefiltrar los valores de municipios a las regiones seleccionadas en la variable de la región, que en mi caso es “Probintzia”, por lo que si tu le has llamado de otra manera, deberás cambiarlo por el nombre de la variable que hayas usado.
Finalmente vamos a crear una tercera variable pero esta vez, cambiamos el tipo de *query* a interval. Esta variable la dejaremos oculta y la utilizaremos para controlar de forma más óptima el número de puntos que se visualizan simultáneamente por cada serie en las gráficas. Esto lo hacemos ya que vamos a manejar una gran cantidad de series, una por cada juego de región/estación y debemos cuidar el rendimiento para que renderizado sea óptimo y no tarde una eternidad:
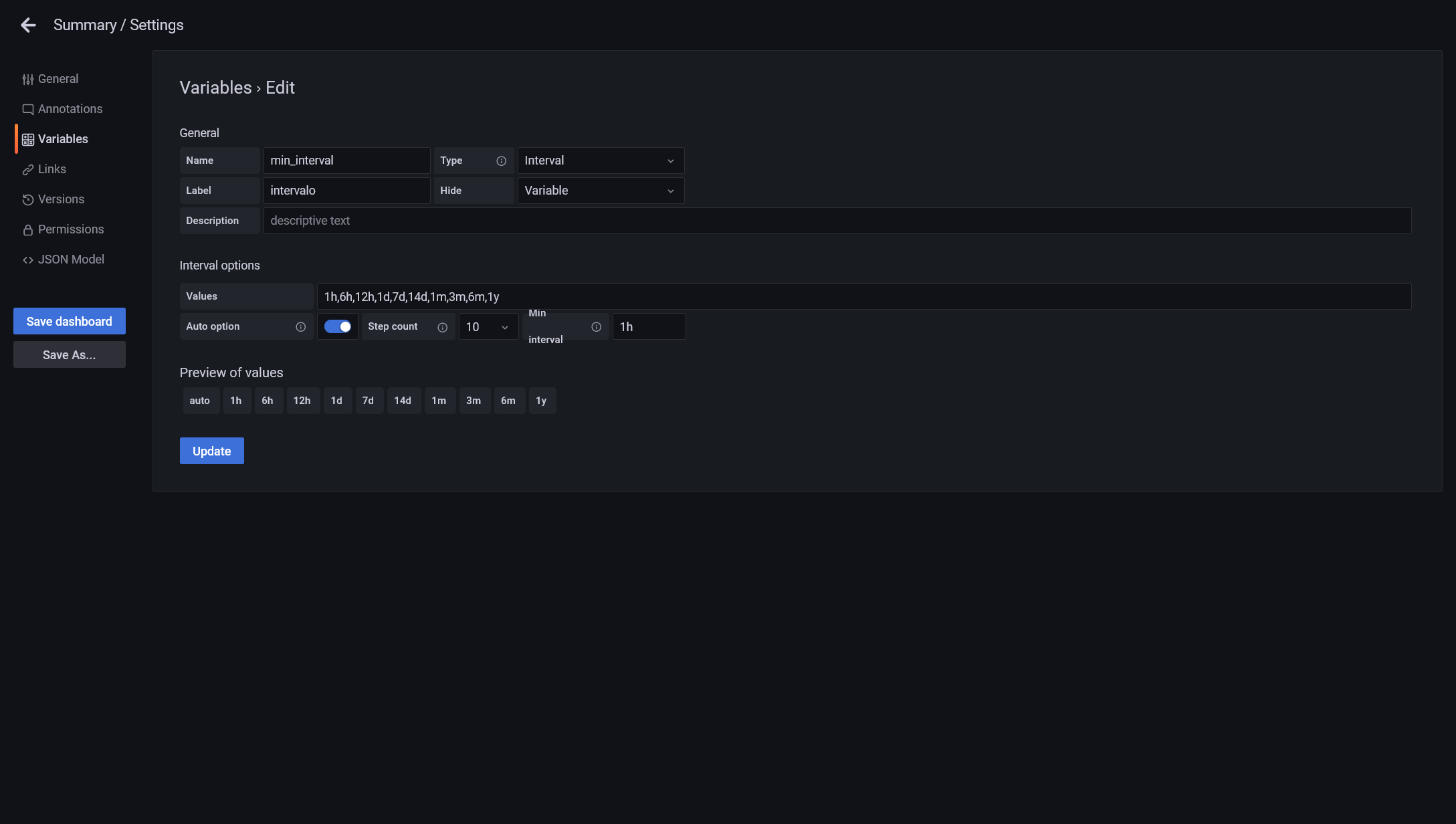
Una vez creadas las variables, podemos ponernos a jugar con las gráficas. La complejidad a la hora de crear los cuadros de mando con dos bases de datos es que tenemos que realizar dos querys simultaneas y juntar los datos respetando las etiquetas de los filtros. El ejemplo más sencillo que podemos hacer tendrías dos querys en una:
t1 = from(bucket: "air")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "iaqi")
|> filter(fn: (r) => r["_field"] == "aqi")
|> filter(fn: (r) => contains(value: r["key"], set: ${Udalerria:json}))
t2 = from(bucket: "air_1d")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "iaqi")
|> filter(fn: (r) => r["_field"] == "aqi")
|> filter(fn: (r) => contains(value: r["key"], set: ${Udalerria:json}))
union(tables: [t1, t2])
|> aggregateWindow(every: ${min_interval}, fn: mean, createEmpty: false)
|> map(fn: (r) => ({_value:r._value, _time:r._time, _field:r.key}))
|> yield(name: "mean")Aquí lo que estoy haciendo es por un lado, crear una tabla temporal t1 con los datos de la tabla Air (últimos 14 días con datos horarios), otra tabla temporal t2 con datos diarios de la tabla Air_1d, y uniendo estas tablas. Dinalmente a la tabla unida le aplico la reducción de intervalo que venga de la variable automática de min_interval reducido calculando la media, y cambio el nombre de cada serie por la etiqueta del nombre de la estación.
De esta manera podremos utilizar las variables para seleccionar la región como filtro:
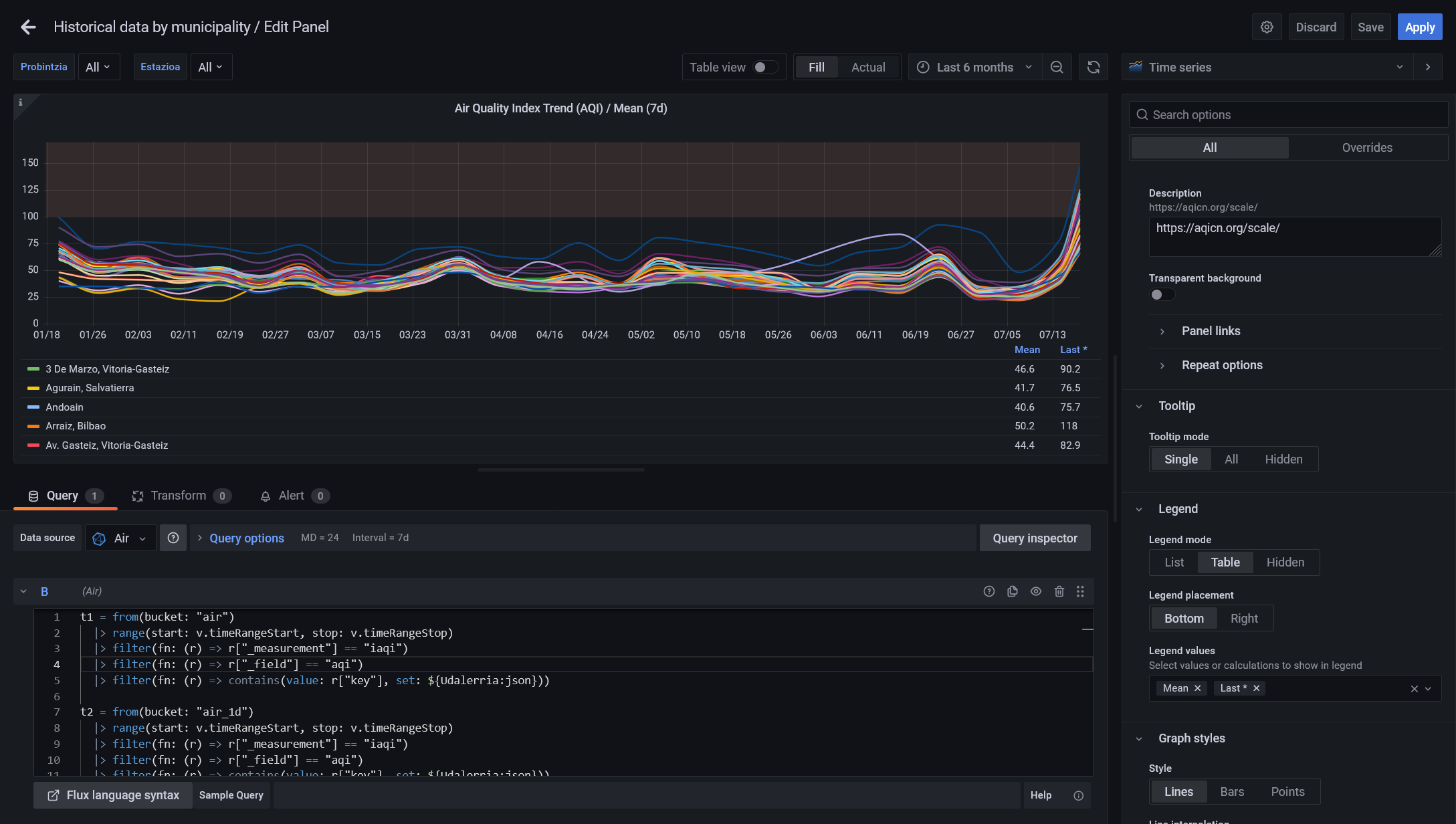
Solo una estación como filtro:
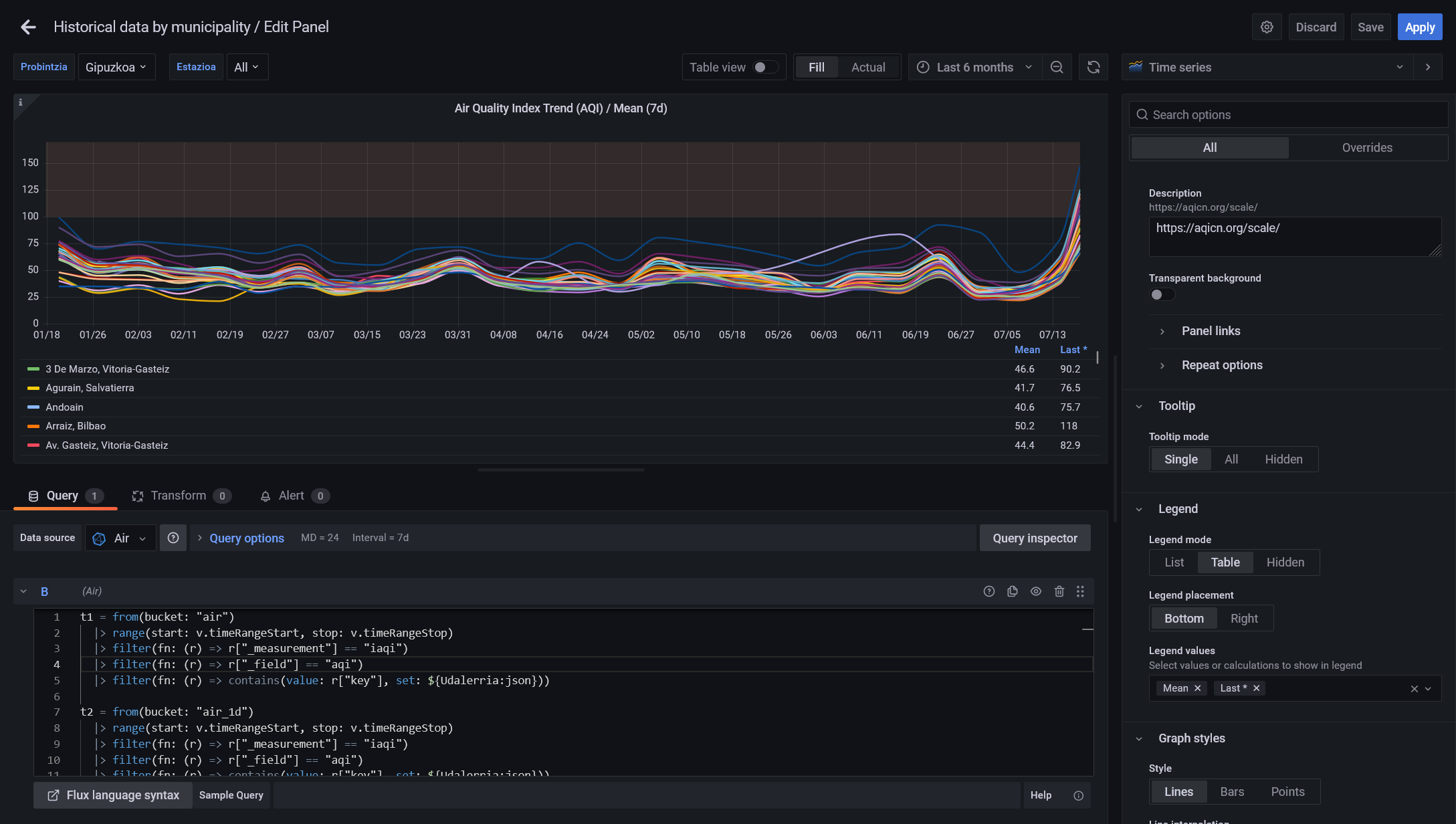
Y ademas cambiando el el periodo a visualizar, el intervalo entre puntos cambiara y el valor se calculará automáticamente realizando una media por intervalo:
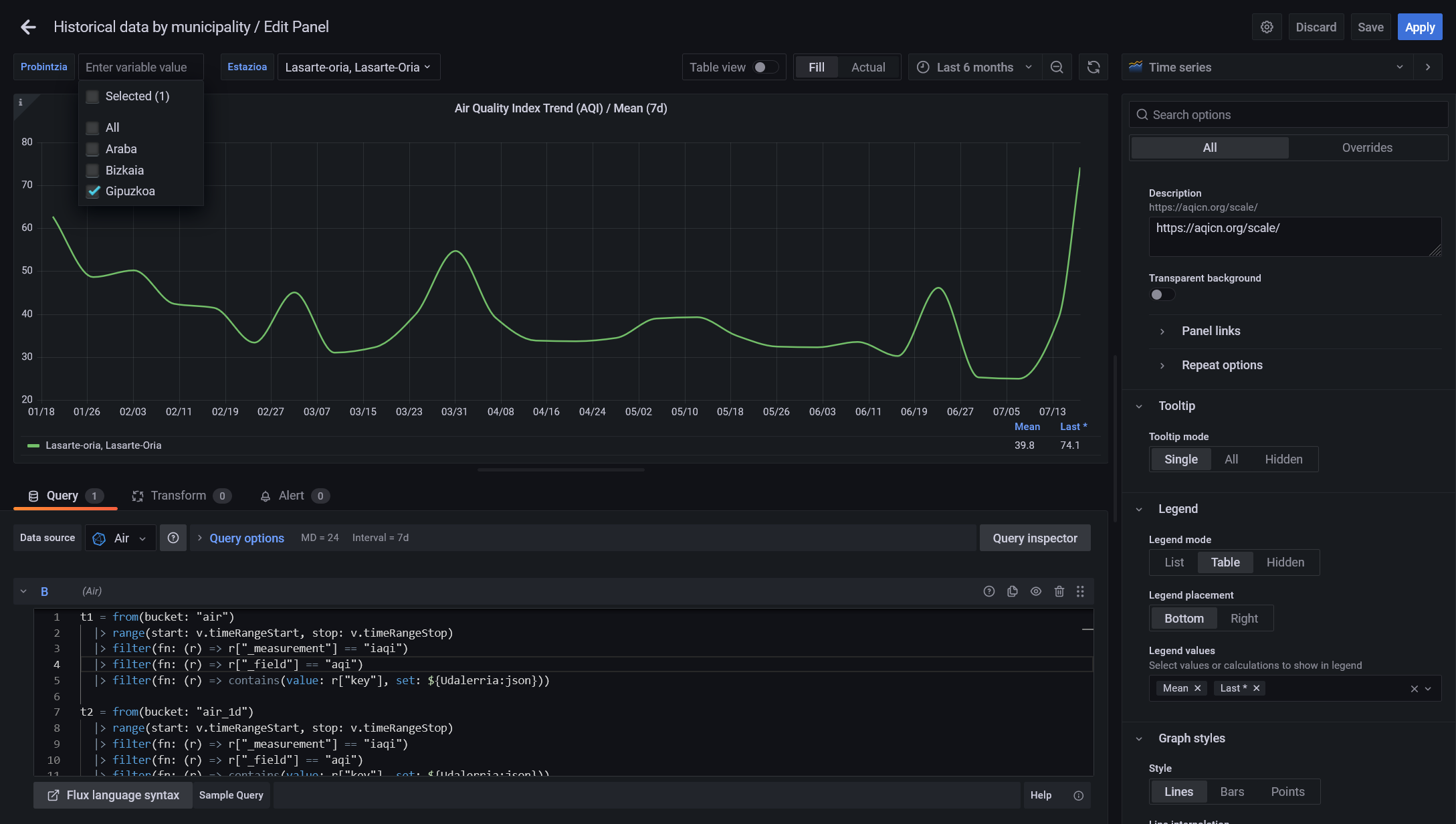
Para ayudaros os dejo el enlace a los Dashboards que he creado y publicado jugando con los formatos de visualización que nos permite Grafana:
-
Sumario: visualización tanto del AQI como de los contaminantes con la media, máximo y mínimo de cada región en formato sombreado.
-
Históricos por estación: el filtrado también se puede hacer por estación, para tener los registros históricos y poder analizar la evolución por cada región y municipio.
-
Vista de mapa: utilizando las coordenadas GPS de posicionamiento de las estaciones y un sombreado de color en función de la calidad del aire, un mapa donde poder ver la situación actual
Si queréis reutilizar estos dashboards simplemente tenéis que descargarlos desde el repositorio que he creado y después importarlos haciendo clic en el menú e importar:
Esto ha sido todo, os dejo en enlace directo anclado en el menú del blog por si más adelante os interesa entrar a ver los cuadros de mando sobre la calidad del aire de Euskadi. Espero que sea interesante, si tienes cualquier duda o complicación no dudes en dejarlo en los comentarios.
Un saludo y nos vemos en el siguiente post.
Nota: algunos de los enlaces a productos o servicios pueden ser enlaces referidos con los que podemos obtener una comisión de venta.