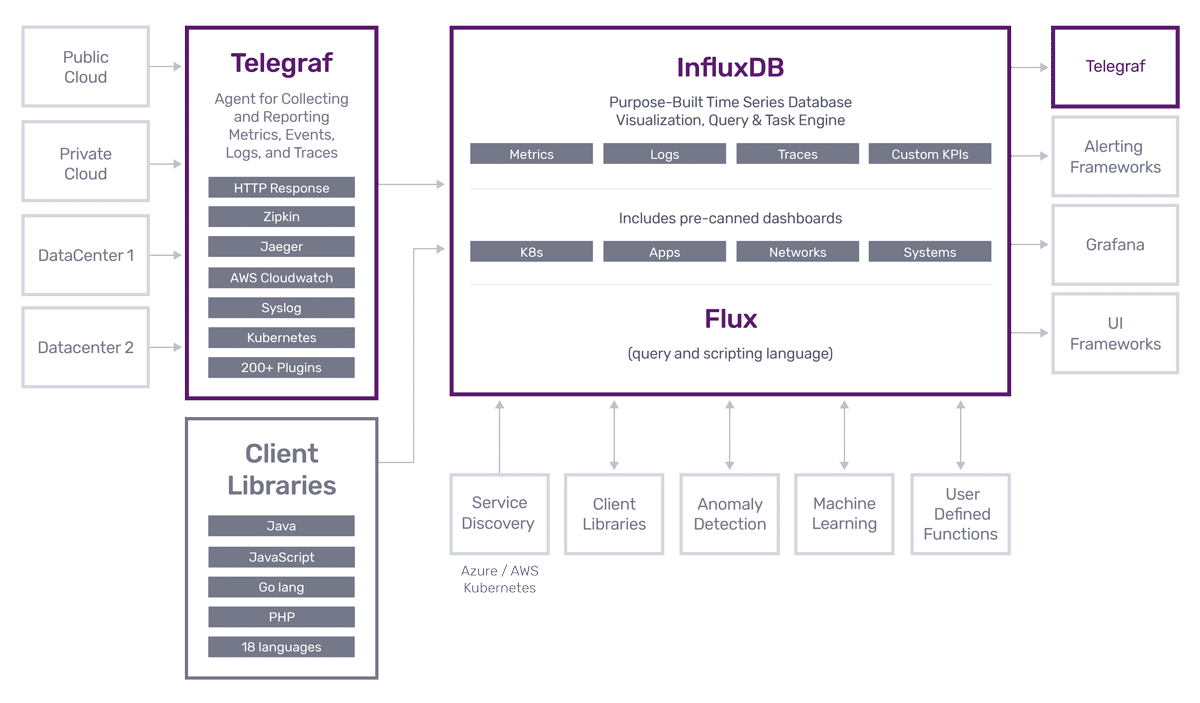
Monitorización de servidores con Telegraf, InfluxDB y Grafana
-
 yayitazale
yayitazale
- June 7, 2021

Ahora que empezamos a tener algo de carga de servicios en nuestro servidor Unraid, es el momento de añadir una monitorización de los recursos para saber cómo afectan al rendimiento estos despliegues que hemos hecho y los futuros que vayamos a hacer.
Esta monitorización se puede hacer de muchas maneras pero yo os voy a explicar cómo hacerlo utilizando las herramientas open source de Influx para recolectar la información del rendimiento e historizar estos datos en una base de datos “especial”, y otra herramienta de software libre llamado Grafana para graficarlos. Además, haremos que estas gráficas se vean como otro dashboard más dentro de Home Assistant.
Antes de empezar, quería comentar que existe un stack ya precocinado y fácil de instalar llamado Grafana Unraid Stack, pero la idea es que en un futuro, podamos utilizar este mismo sistema para graficar valores de sensores de Home Assistant con un formato más bonito y funcional que las gráficas embebidas que traer por defecto, por lo que te recomiendo que sigas los pasos de esta guía y así aprendas cómo funciona, que es de lo que se trata este blog.
(Foto de portadaTaylor Vick en Unsplash)
TOC
- Bases de datos de tipo timeseries con InfluxDB
- Recolección de datos con Telegraf
- Gráficas y más gráficas con Grafana
- Publicar el microservicio en Nginx Proxy Manager
- Dashboards embebidos en Home Assistant
Bases de datos de tipo timeseries con InfluxDB
Lo primero que vamos a hacer para poner en marcha nuestro sistema de historización y monitorización de UnRaid es levantar nuestra base de datos donde guardaremos estos datos.
Como las métricas que vamos a capturar van a ser todas de tipo tiempo - valor, o mejor dicho, timestamp - valor, las bases de datos de series temporales son las que mejor se adaptan para tener un buen rendimiento de escritura y lectura. Podríamos usar bases de datos relacionales, pero a medida que las tablas crezcan tendremos problemas de rendimiento, por lo que vamos a optar por InfluxDB, una BBDD open source muy potente y fácil de instalar y gestionar.
Antes de instalar nada, vamos a ver los conceptos básicos de InfluxDB:
- InfluxDB 1 Vs. InfluxDB 2: la primera versión de esta BBDD se publicó allá por el 2013. Desde entonces, Influx ha crecido como organización hasta convertirse en uno de los actores más importantes en cuanto a bases de datos de series temporales (muy útil para el IoT). A finales del año pasado, se publicó un “mayor change”, InfluxDB 2.0, con uno de los cambios más importantes que es el paso del lenguaje InfluxQL a Flux. Aunque para muchos, el uso de InfluxDB 1.X siga siendo más sencilla, voy a aventurarme a explicaros la instalación y uso de InfluxDB 2.0 y Flux.
- Flux: es el lenguaje que vamos a utilizar a la hora de hacer las “querys” a la BBDD, ya que la escritura de datos lo hará Telegraf por nosotros.
- Organizations: influx está pensado para un posible entorno empresarial, por lo que nos obliga a crear organizaciones, que serán en el fondo, una especie de “armarios” de datos estancos donde guardaremos los diferentes cubos de cada organización por separado. Sirve sobre todo para dividir los accesos ya que como veremos, los tokens de acceso serán siempre dirigidos a una organización/cubo en concreto. Si vienes de SQL, esto sería una BBDD como tal.
- Bucket: los cubos son las tablas donde almacenaremos los datos. Podremos crear tantos cubos como queramos para cada organización.
- Retention policy: a cada cubo le especificaremos por cuanto tiempo queremos guardar los datos. Esto es muy útil ya que podremos almacenar por periodos diferentes los datos con diferentes necesidades.
- Tasks: otra función de Influx es la posibilidad de crear tareas para jugar con los datos. Ejemplos: disminuir la resolución de unos datos a medias horarias y guardarlas en otro bucket diferente, crear datos calculados sumando dos señales, etc.
- Kapacitor: es el servicio embebido que realiza las tareas.
- Chronograf: es la interfaz web para gestionar influxdb y kapacitor.
- Authentication token: los permisos de lectura y escritura a diferentes organizaciones y buckets se crean en Chronograf y en vez de ser los clásicos usuario/contraseña, son tokens únicos.
Bien, ahora que tenemos los conceptos básicos claros, vamos a nuestra App store de UnRaid, buscamos por “Influxdb” e instalamos la versión oficial:
La plantilla ya viene lista y no hace falta cambiar nada por lo que aceptamos y esperamos que se baje la imagen y se levante el contenedor:
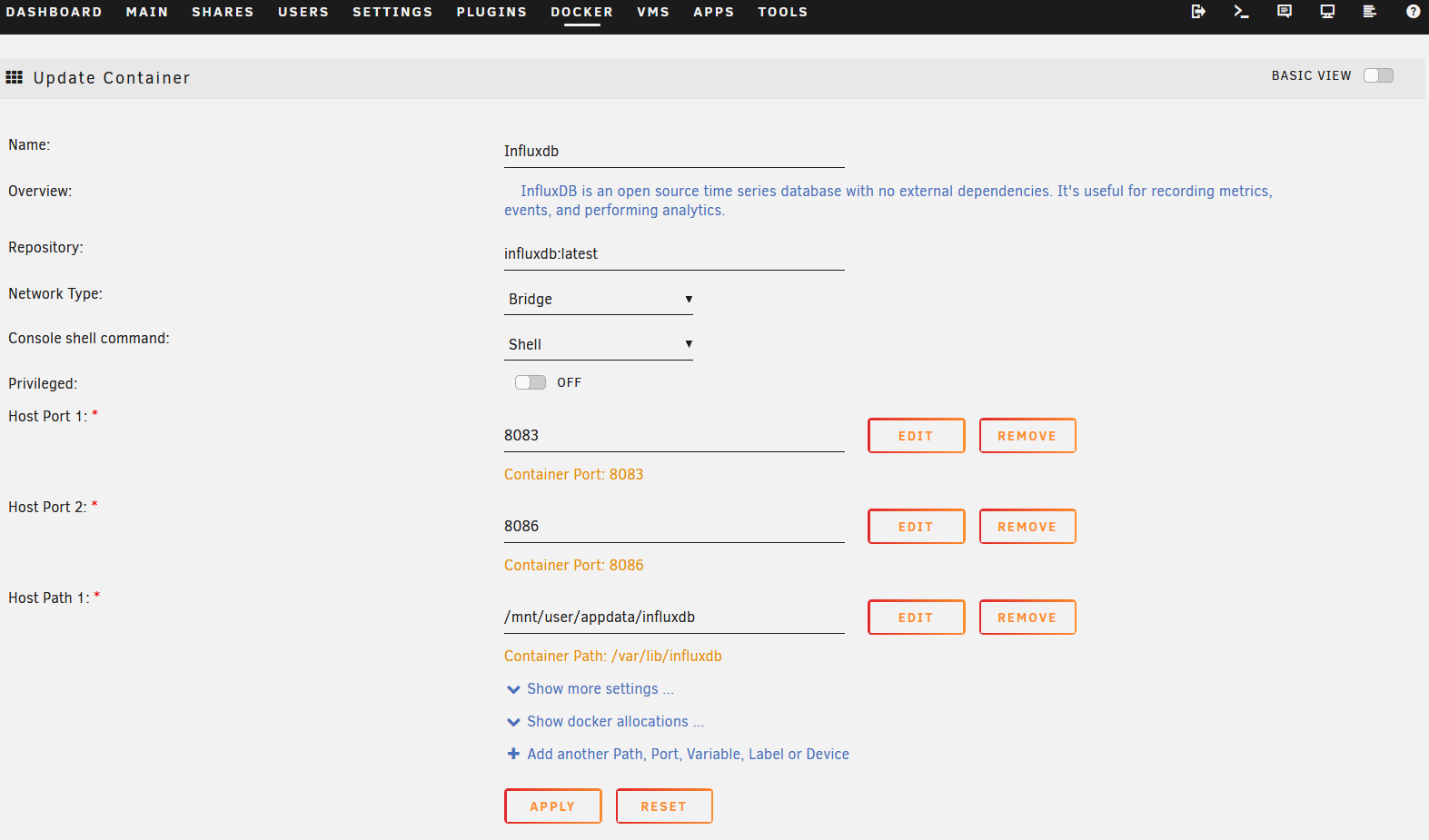

Ahora como siempre, vamos a la pestaña Docker y en el contenedor de InfluxDB hacemos click en el logo y vamos WebUI para que nos lleve a Chronograf:
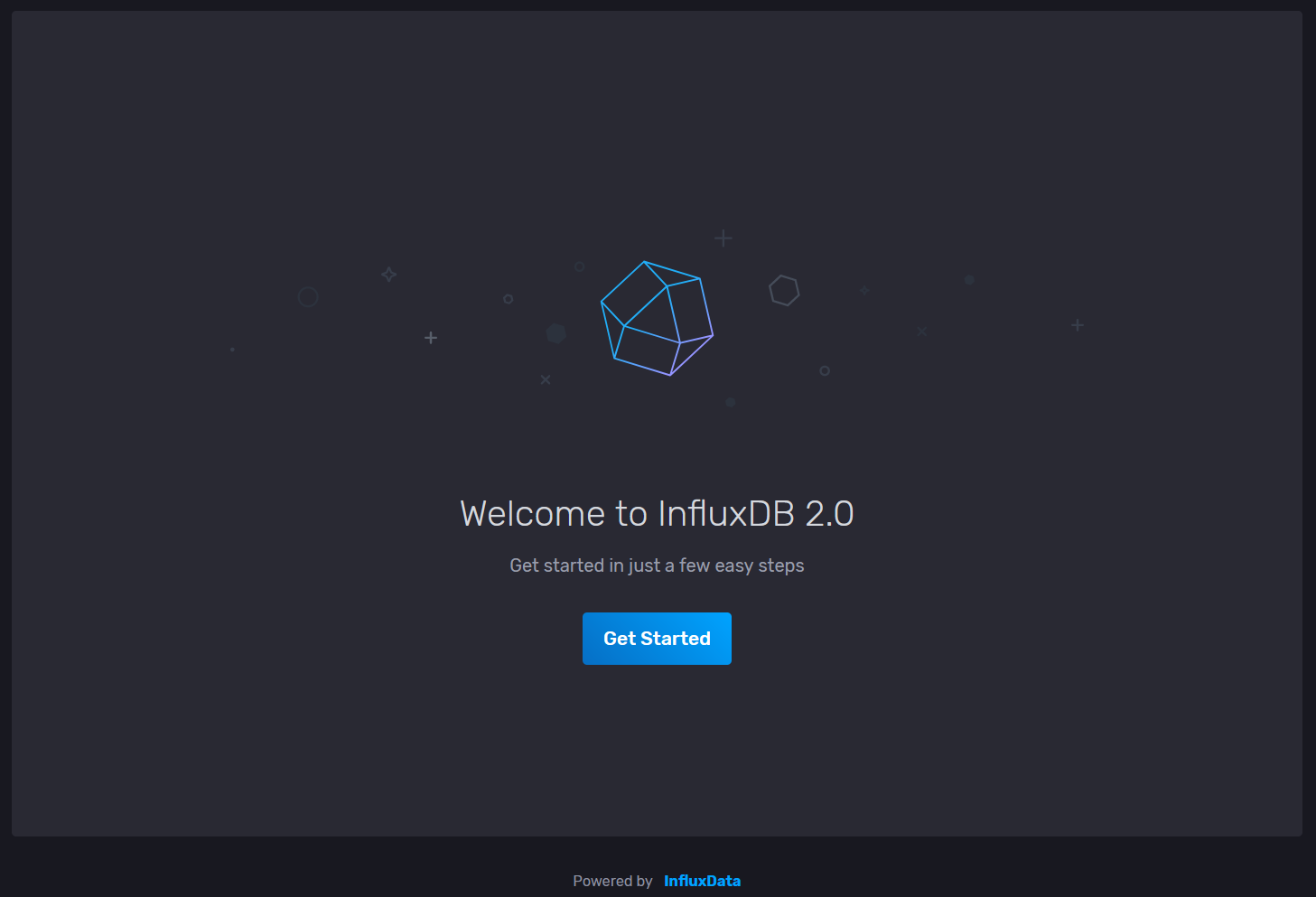
Nos encontraremos con un clásico Welcome Aboard en el que tendremos que crear una cuenta de Administrador, una organización y un cubo. Las credenciales las podemos crear y guardar en nuestro gestor de contraseñas para que no se nos olviden. En mi caso, a la organización le he llamado Home y el primer bucket se llamará Unraid ya que es donde guardaremos las métricas del propio server:
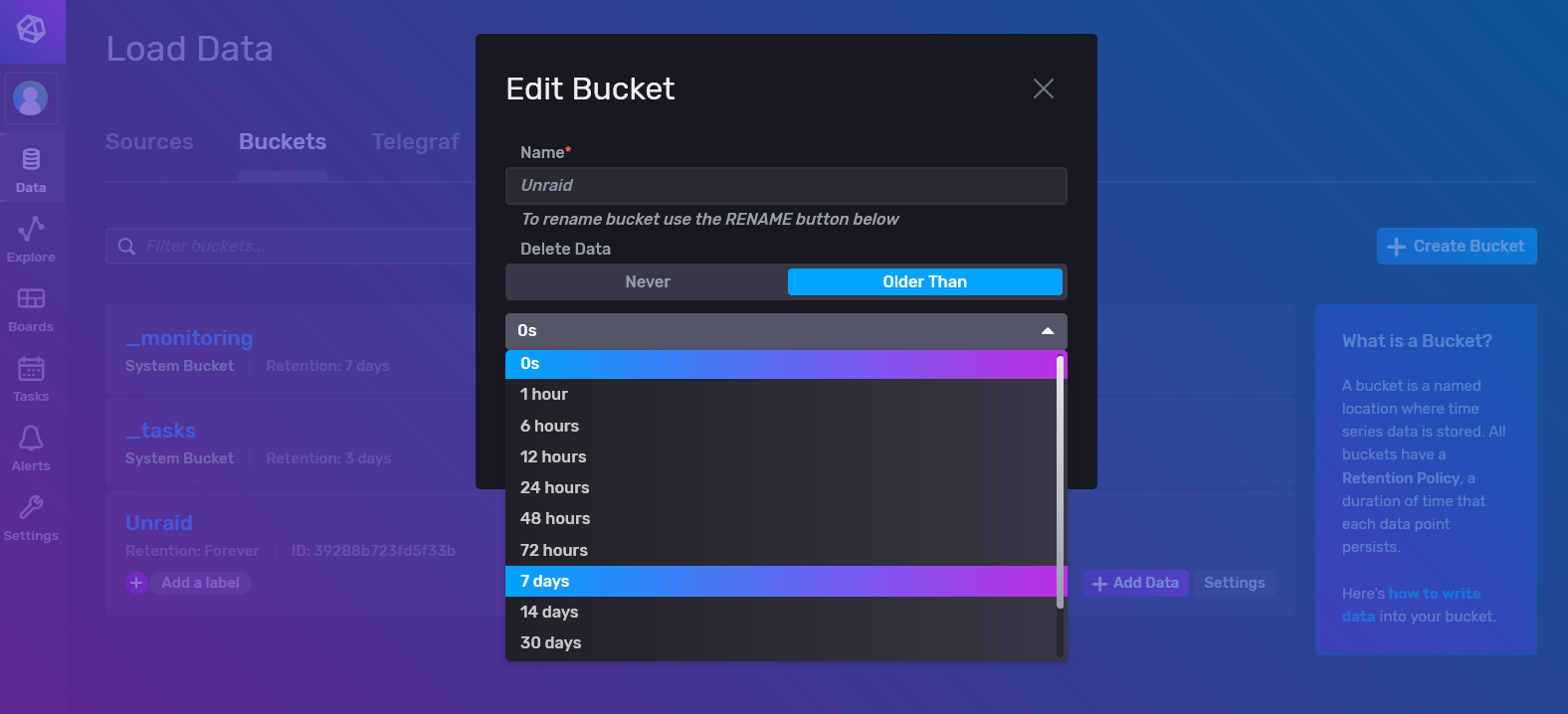
Hacemos click en Advanced (tranquilo, yo te voy a guiar para que no te pierdas) que nos llevará directo a la página de configuración de los buckets. Ya que las métricas que vamos a guardar no van a ser muy interesantes para analizar cuando pase el tiempo, vamos a cambiar la retention policy a 7 días, de forma que se vayan limpiando los datos antiguos de forma automática. Para esto, hacemos click en el boton settings del bucket Unraid y seleccionamos 7 days (o el tiempo que queráis vosotros):
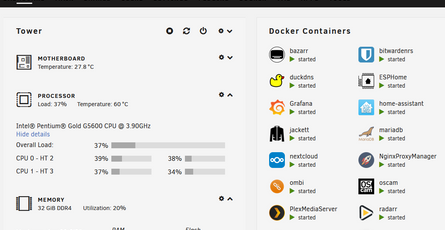
Ahora vamos a la pestaña Telegraf y vamos a crear una plantilla preconfigurada de Telegraf, de forma que cuando vamos a instalar el colector de datos simplemente usemos dicha plantilla sin tener que tocar nada. Le damos a Create y seleccionamos System para que recoja los datos de rendimiento del sistema y Docker para que nos monitorice los contenedores y su impacto:
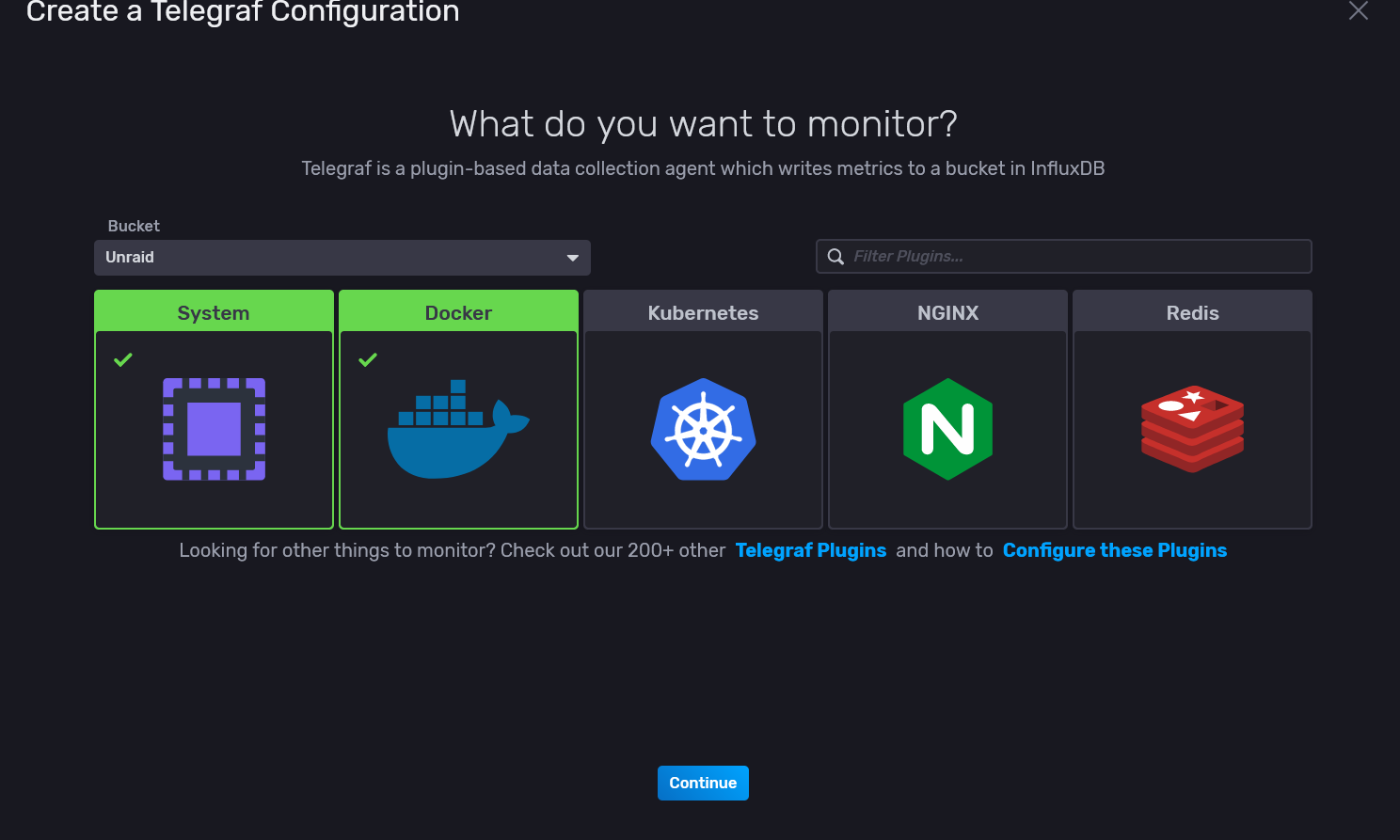
Le ponemos un nombre a la configuración y vemos que Docker aparece en gris en la lista de la izquierda de los componentes a monitorizar. Si hacemos clic sobre él, nos lleva a la configuración que falta, que es la de definir el endpoint de docker. En UnRaid, ese endpoint es el siguiente:
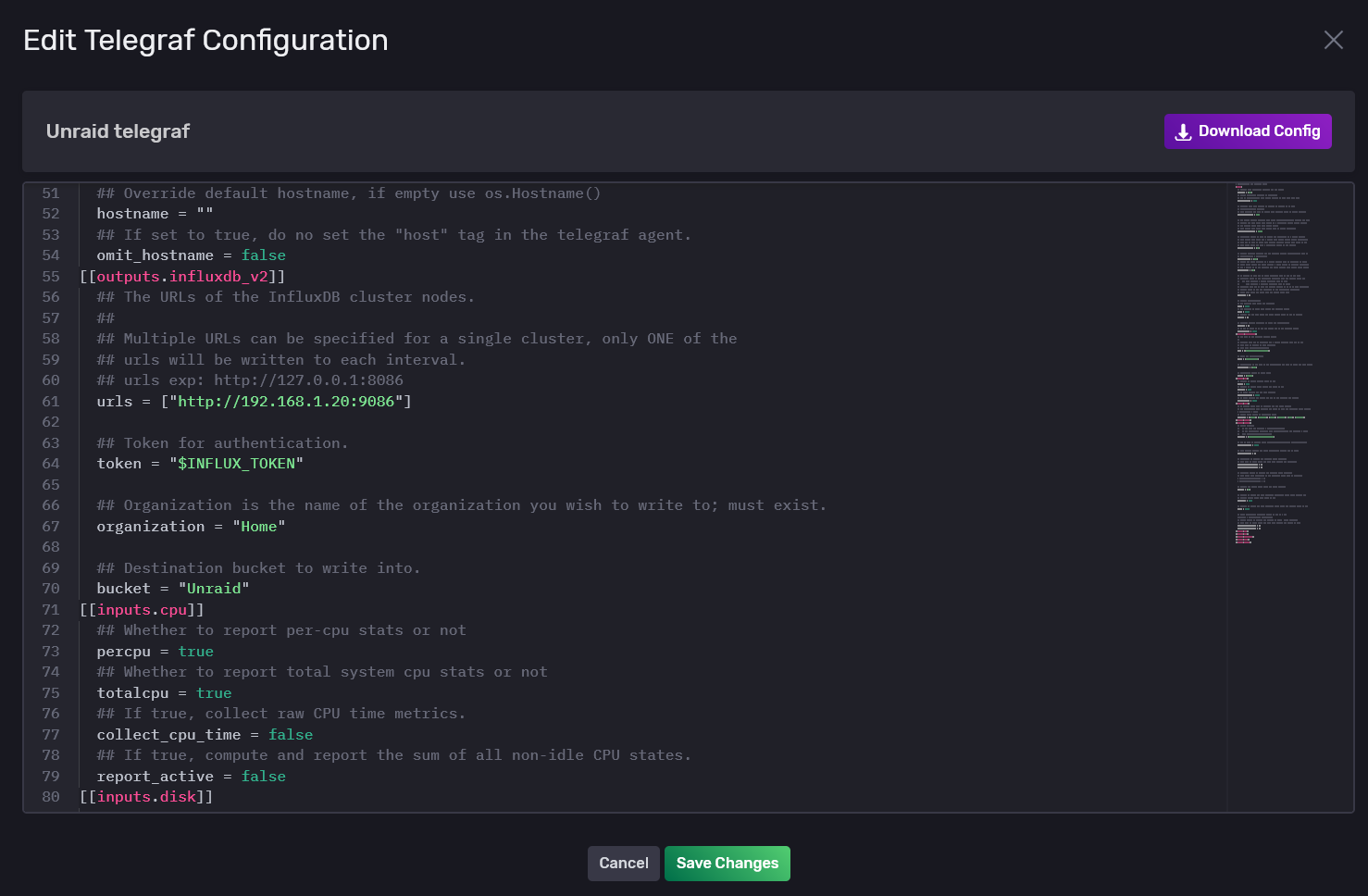
unix:///var/run/docker.sockAñadimos esto, aceptamos y finalizamos la configuración. Ahora tenemos que copiar el token de acceso que acabamos de generar en un block de notas. Aceptamos y hacemos click sobre Unraid telegraf, lo que nos abrirá el propio archivo ya generado. Los descargamos y abrimos con nuestro editor VsCode, vamos a la línea donde pone token y quitamos la variable y lo metemos directamente:
Sin cerrar esta pestaña del navegador, vamos al siguiente paso de instalar telegraf.
Recolección de datos con Telegraf
Telegraf es un agente liviano que podemos instalar y ejecutar prácticamente en cualquier tipo de entorno (Windows, Linux etc) y que no solo permite capturar métricas de rendimiento de servidores, sino que sirve también como conector entre cientos de plataformas como Nagios, Syslog, Kubernetes, Collectd, JSON, MQTT, CSV etc.
Está pensado para funcionar directamente con InfluxDB como base de datos donde historizar los datos, por lo que su integración es muy sencilla. Como ya tenemos instalado InfluxDB y creado un token de acceso y un archivo de configuración, antes de instalar tenemos que crear la ruta y copiar este archivo a dicha ruta.
Para hacer esto, vamos al explorador de archivos de windows y vamos a la ruta de \IP-DE-UNRAID\appdata, suponiendo que tienes el share accesible, y creamos la carpeta telegraf.
Copiamos el archivo unraid_telegraf.conf que nos hemos descargado a esta carpeta y lo renombramos por telegraf.conf
Ahora ya si, vamos a instalar el agente de telegraf. Para ello, vamos a la app store de UnRaid y buscamos pos telegraf:
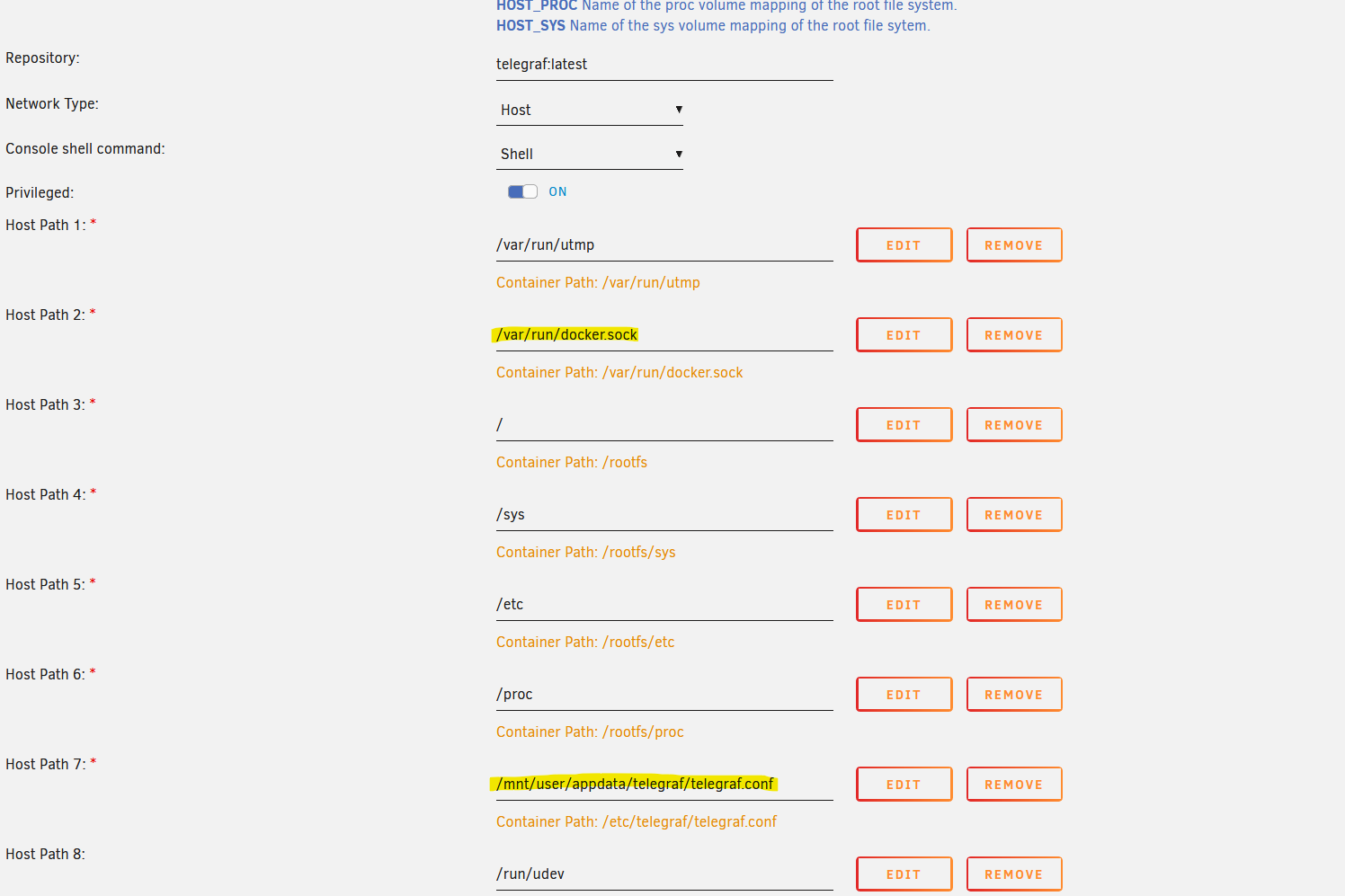
Lo instalamos sin cambiar nada ya que la plantilla ya tiene la ruta del endpoint de docker y la ruta del archivo de configuración:
Al arrancar el contenedor, si hemos hecho todo bien en el log deberemos ver algo tal que así (sin errores en rojo):
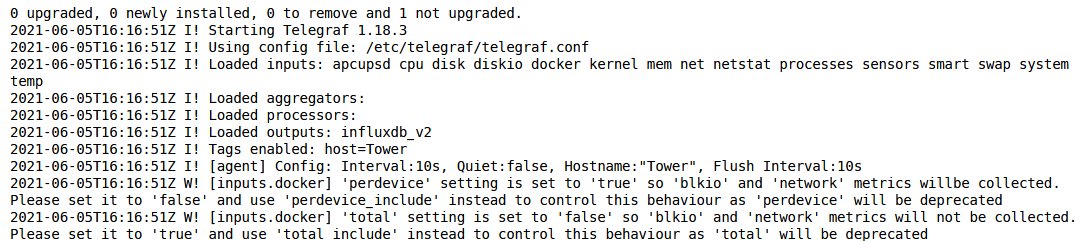
Bien, ya estamos historizando los datos de nuestro sistema. Antes de pasar al siguiente punto, visualización, vamos a crear un token solo de lectura que utilizaremos para leer los datos. Para ello, volvemos a la pestaña del navegador donde tenemos Chronograf, vamos a Token -> Generate Token y lo configuramos con permisos solo de lectura en el bucket Unraid tal que así:
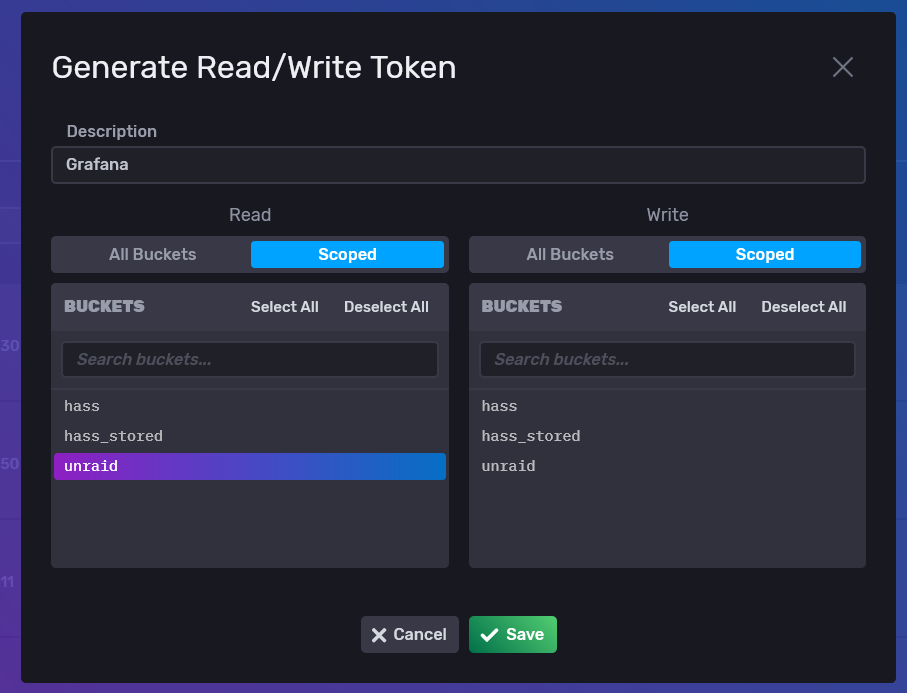
Y después, hacemos click en el nombre del token y lo copiamos en un block de notas para usarlo después.
Gráficas y más gráficas con Grafana
Grafana se ha convertido en uno de los motores de visualización de datos más utilizados, sobre todo en el mundo de la monitorización de activos informáticos, pero cada vez más está cogiendo fuerza su uso en otro tipo de entornos como la monitorización de procesos industriales. No puedo dejar de mencionar otras plataformas muy interesantes de análisis de datos, como ThingsBoard, Kibana o Plotly, todos ellos muy potentes en su área pero no idóneos para esta tarea.
En Grafana, existe una versión de pago en su cloud, pero en nuestro caso vamos a instalar la versión completamente libre. Esto, de nuevo, lo haremos desde la app store de UnRaid:
En la configuración del contenedor no tocamos nada y arrancamos el servicio. Vamos a la WebUI y entramos con el usuario y contraseña admin/admin, tras lo cual, nos pedirá una nueva contraseña que guardaremos en nuestro vault:
Grafana tiene muchas posibilidades de configuración que no voy a comentar en este manual ya que nos podríamos eternizar. Os dejo el enlace a su documentación para que le echéis un ojo ya que es muy completa.
Nosotros lo que vamos a hacer es añadir como fuente de datos el bucket de Unraid que estamos alimentando con datos en InfluxDB, y después crear un dashboard para visualizar estos datos. Lo primero entonces, es ir a Configuration -> Data Sources y vamos a Add Data Source:

Entre los orígenes de datos vemos InfluxDB, lo seleccionamos:
Ahora debemos rellenar los siguientes datos:
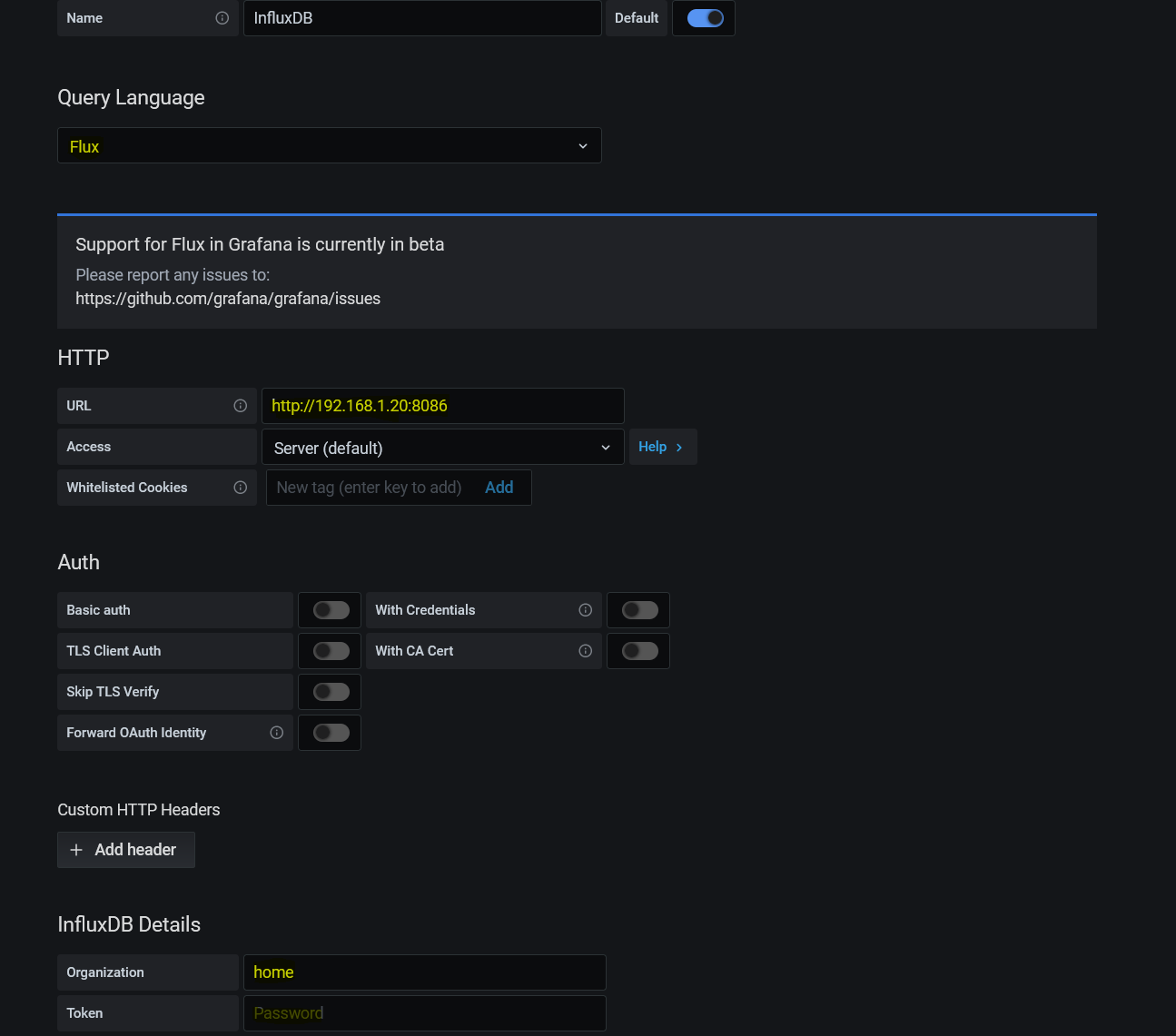
- Query Language: Flux
- URL: http://ip-de-unraid:8086
- Basic Auth: lo deselecionamos
- Organization: el nombre de organización de influx, en este caso, Home
- Token: aquí metemos el token de solo lectura que hemos creado antes
- Main Bucket: el que hayamos puesto, en mi caso Unraid
Le damos a Save & Test y debería de decir que todo ha ido correctamente y ha encontrado el bucket.

Por fin, ya tenemos todo listo para graficar nuestras señales. Vamos Create -> Dashboard. Ahora, vamos a crear un panel, seleccionando el botón de Add empty panel. Nos abrirá la pantalla de creación de paneles donde tendremos tres bloques:
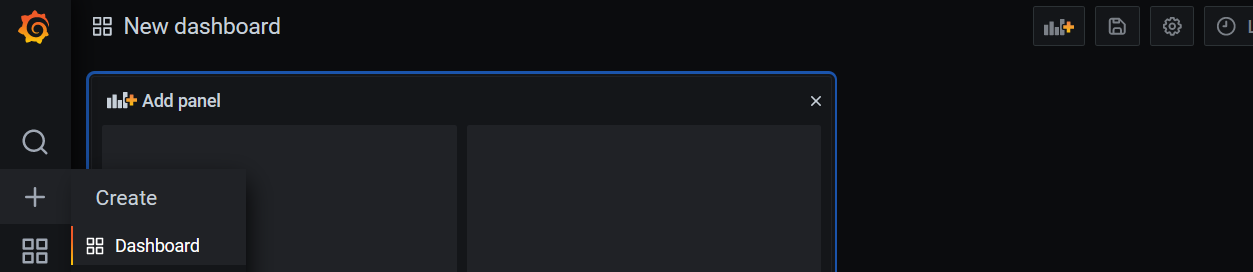
- La visualización de cómo va a quedar en panel
- El campo donde añadir la query de los datos a mostrar
- Donde configuraremos el tipo de visualización y características del panel.
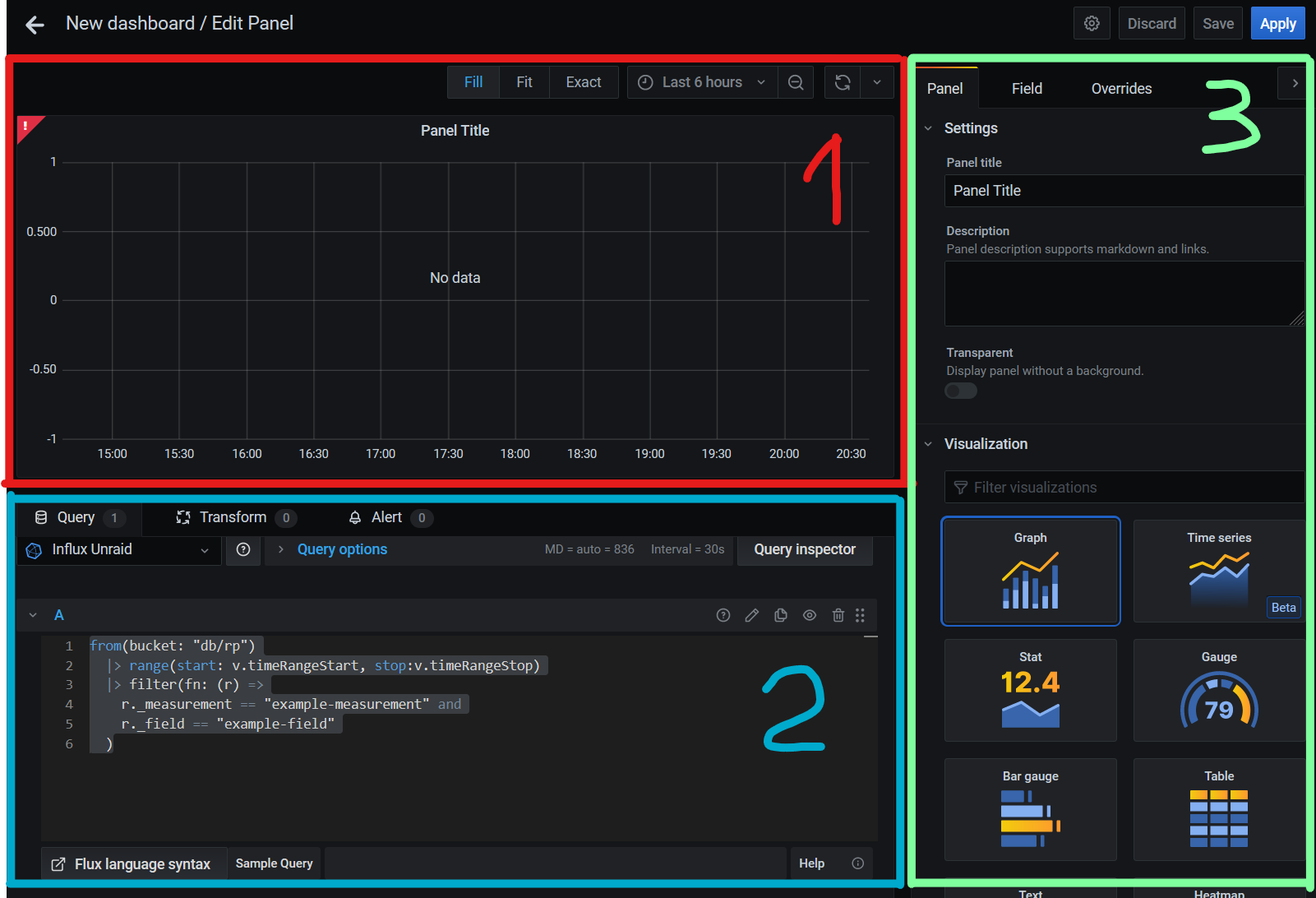
Para los que ya sabéis programar, os voy a explicar muy brevemente cómo se construye una query con Flux. En la imagen anterior podéis ver un ejemplo de query simple. Vamos a ver una query algo más completa:
from(bucket: "db/rp")
|> range(start: v.timeRangeStart, stop:v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "example-measurement" and
r._field == "example-field"
)
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> map(fn: (r) => ({
_value: r._value,
_time: r._time,
name: "Value of example field"
}))
|> yield(name: "mean")Lo primero es definir el bucket de donde sacamos el dato. Luego, metemos las cláusulas de filtrado y finalmente hacemos las transformaciones que queramos como agrupar datos o meter aliases.
Al ser bases de datos de series temporales, lo más habitual es que el primer filtrado sea el rango de tiempo que queremos obtener. En grafana, en la zona 1 de la pantalla de creación del panel verás que existe un time-picker, con el cual podemos jugar a cambiar este rango. Para que esto funcione, en vez de pasar el rango de forma explícita en la query lo que hacemos es pasar la variable que genera grafana del inicio del rango de tiempo v.timeRangeStart y el del final, v.timeRangeStop.
Además, para hacer que el motor de visualización de grafana trabaje más rápido, podemos añadir la transformación de reescalado de la resolución, usando la función aggregateWindow. Aquí, la ventaja es que el propio motor de grafana es capaz de adaptar la resolución de forma automática a la escala de tiempo que le pidamos.
A modo de ejemplo, si le pedimos una escala muy pequeña, la última hora, nos podría una resolución de puntos de la media de cada 10 segundos. Sin embargo, si le pedimos los datos la la última semana, nos sacará una media de cada 3 horas. Esto es muy interesante ya que nosotros vamos a recoger el estado del servidor cada 10 segundos (lo puedes cambiar en el telegraf.conf) y al hacer zoom out no nos interesa tener tanto detalle sino ver las tendencias.
Para poder hacer esto, en la función de datos agregados metemos como resolución la variable de grafana v.windowPeriod con la función agregada mean, que será la media.
En los filtrados por campo, lo que haremos es simplemente filtrar por el nombre de la variable que queremos graficar (% de uso) y el tag correspondiente al elemento (disco duro 1, cpu 2, etc).
El mapeo final es la forma de pasar la serie temporal obtenida a grafana con un alias (name).
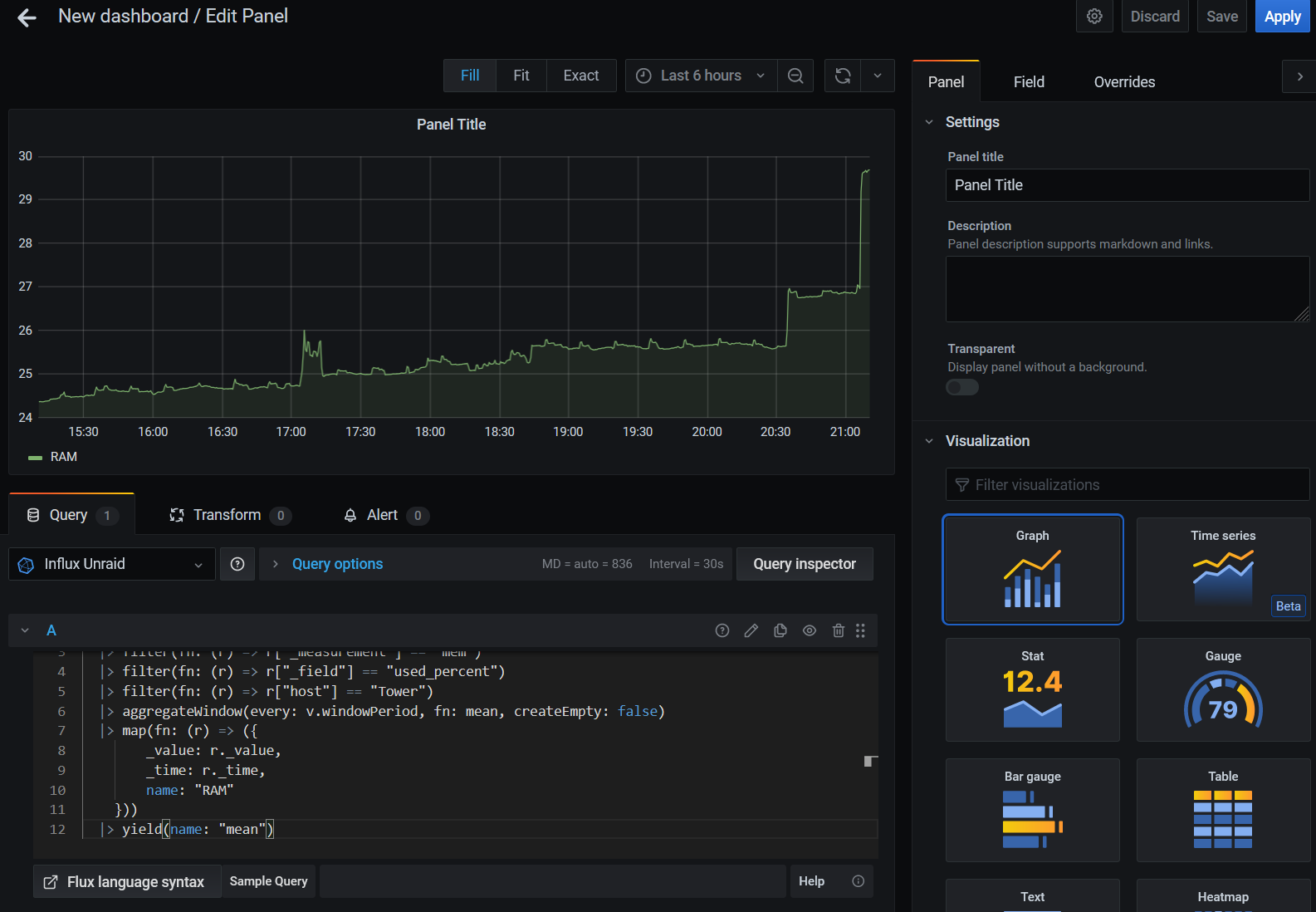
Para empezar, vamos a graficar el porcentaje de uso la RAM, con la siguiente query:
from(bucket: "unraid")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "mem")
|> filter(fn: (r) => r["_field"] == "used_percent")
|> filter(fn: (r) => r["host"] == "Tower")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> map(fn: (r) => ({
_value: r._value,
_time: r._time,
name: "RAM"
}))
|> yield(name: "mean")Ahora deberías ver una línea con la gráfica:
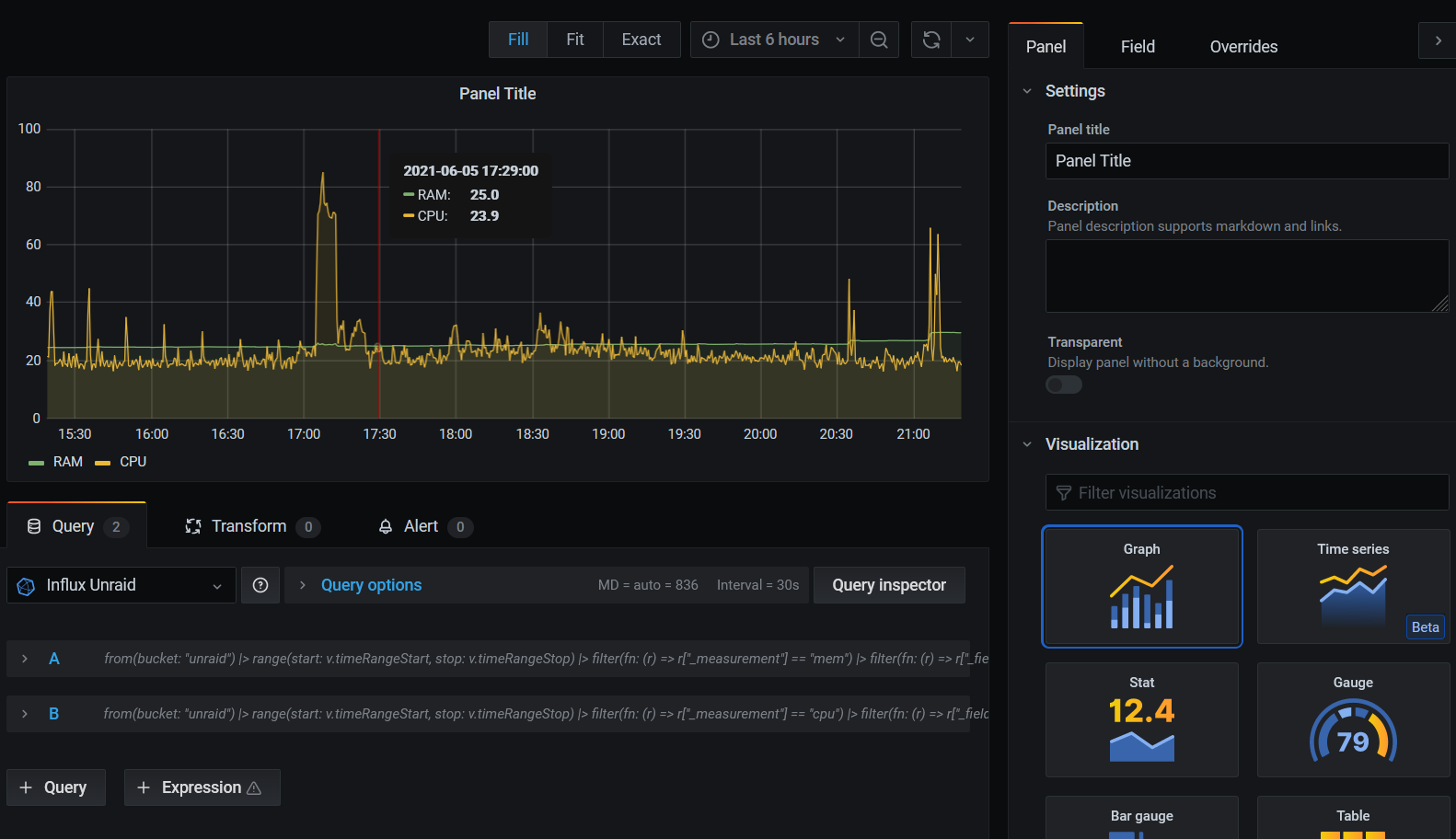
Para el uso de CPU, el % de uso viene separado por system, user etc, por lo que lo más fácil es transformar el dato siendo el % usado = 100 - % sin uso (iddle). La query sería la siguiente:
from(bucket: "unraid")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["_field"] == "usage_idle")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> filter(fn: (r) => r["host"] == "Tower")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> map(fn: (r) => ({
_value: 100.0 - r._value,
_time: r._time,
name: "CPU"
}))
|> yield(name: "mean")Puedes añadir esta query en la misma gráfica o bien crear otra nueva:
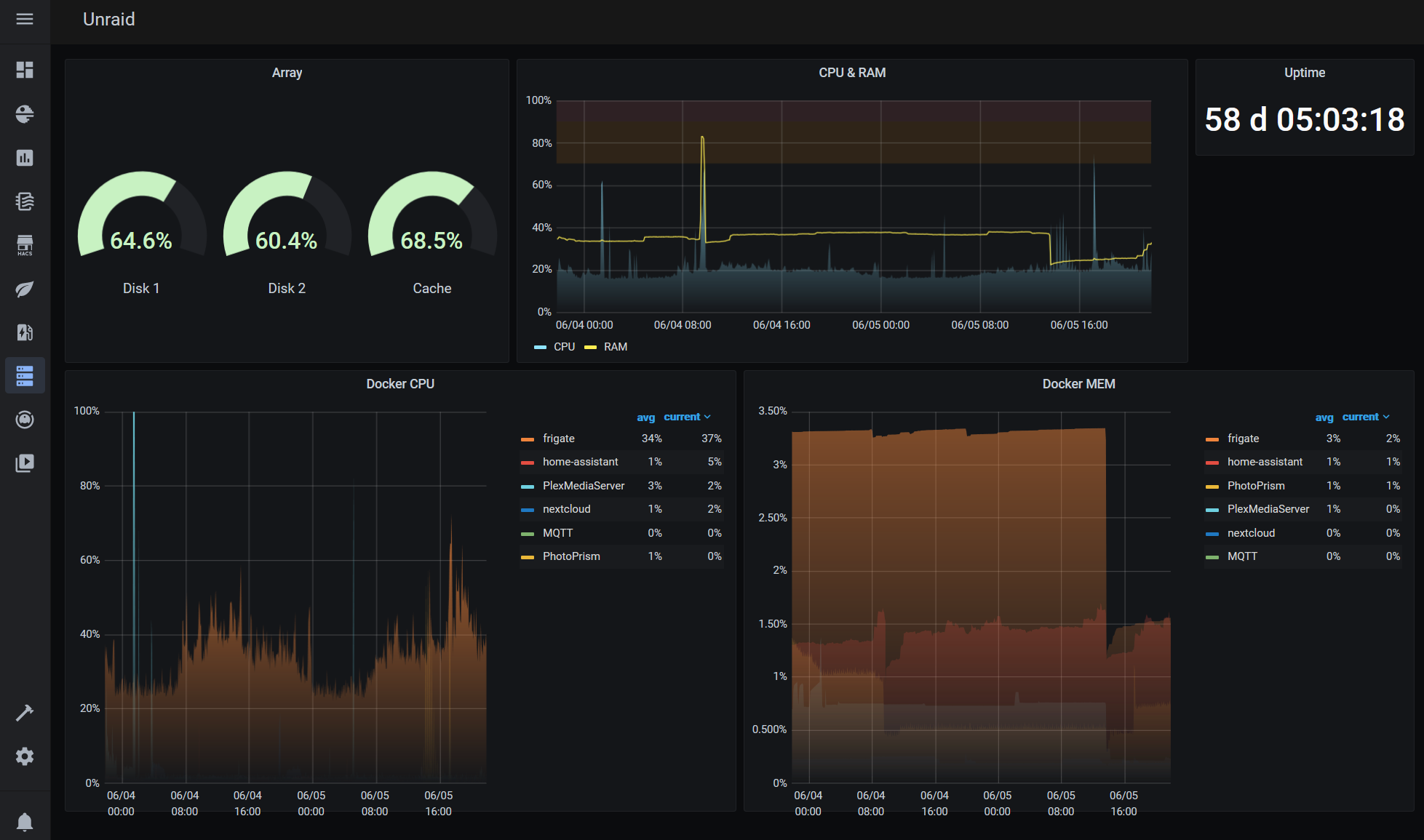
Te invito a que ahora pruebes a cambiar el modo de visualización, colores, juegues con el timepicker etc. Como podrás comprobar, el potencial de Grafana es tremendo y se pueden hacer dashboards a gusto de cada uno. Para ayudarte un poco en la tarea, te dejo este archivo con una copia de mi dashboard de Unraid.
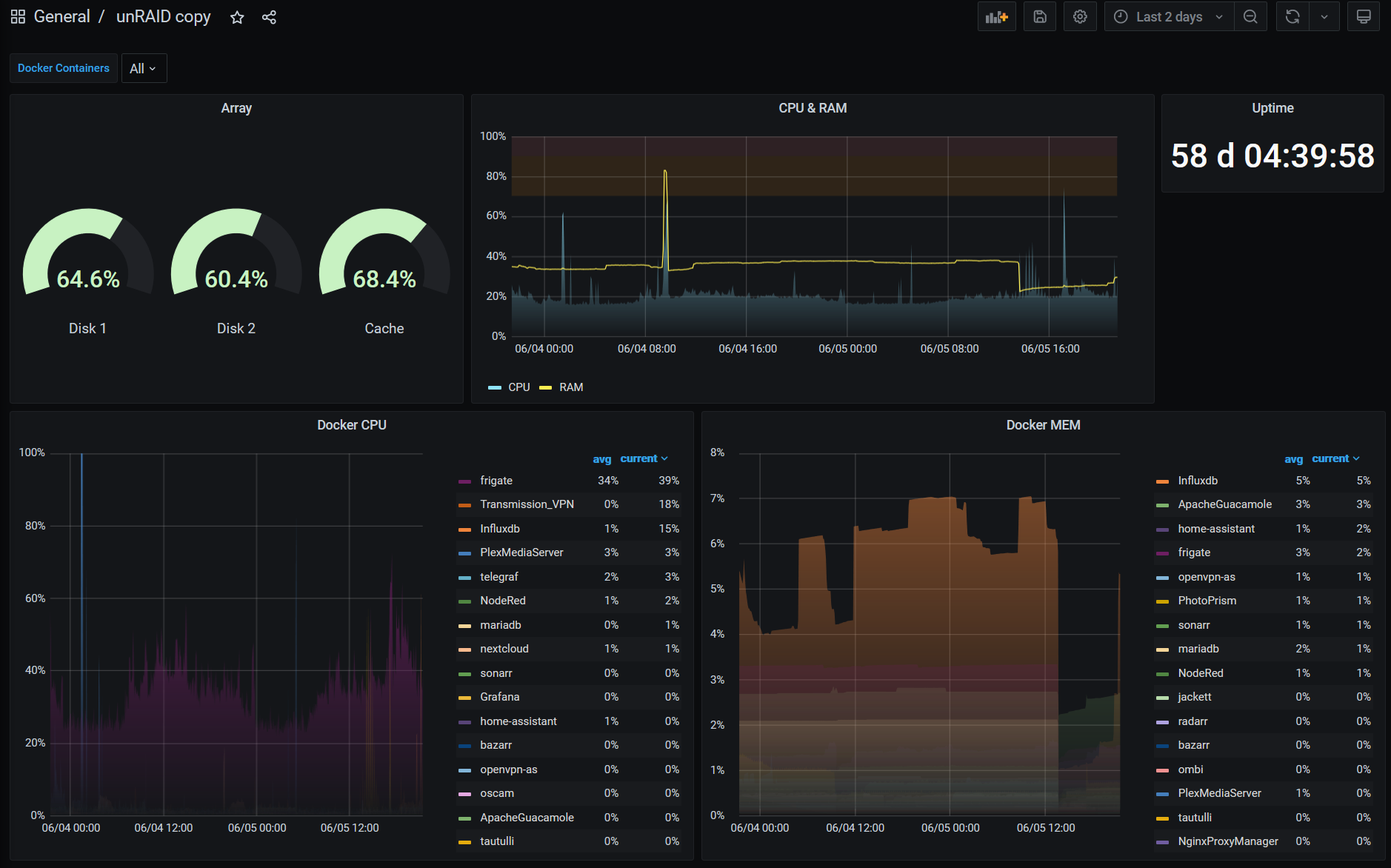
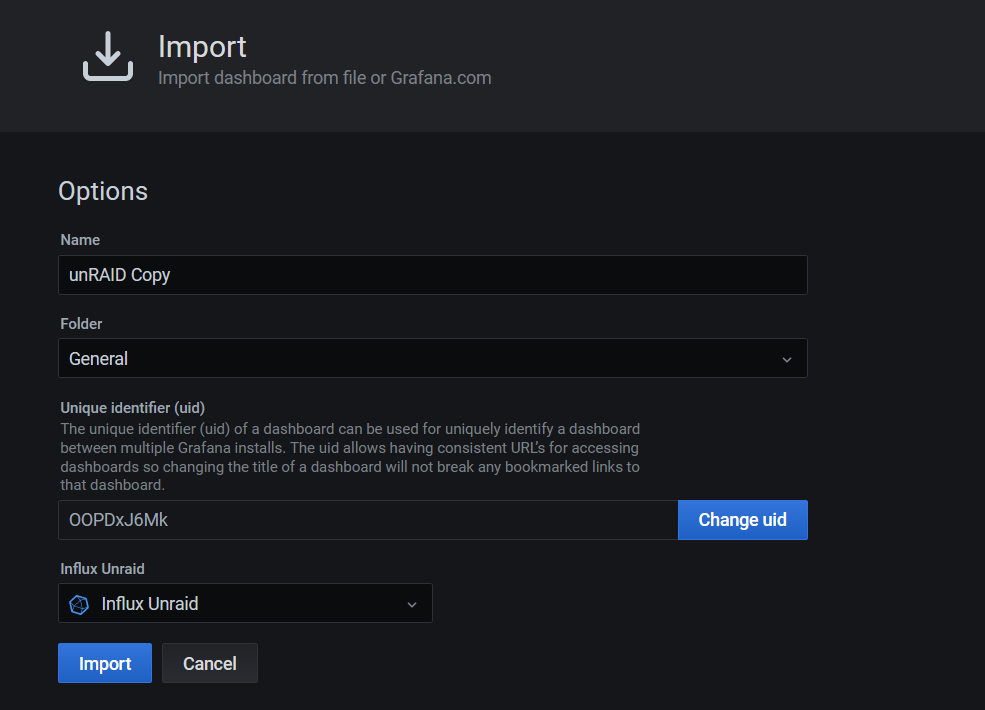
Para usarlo, debes ir Create -> Import, seleccionar el fichero, y una vez cargado, tendrás que apuntar a tu bucket de Unraid. Como puedes ver en la imagen, he añadido una variable que detectará automáticamente los servicios docker que tengas levantados y te permite filtrar entre los contenedores que quieras monitorizar.
Publicar el microservicio en Nginx Proxy Manager
Aunque esto ya lo hemos visto anteriormente, vamos a repasarlo. En Nginx proxy manager rellenamos los datos de acceso del contenedor y generamos un nuevo certificado.:
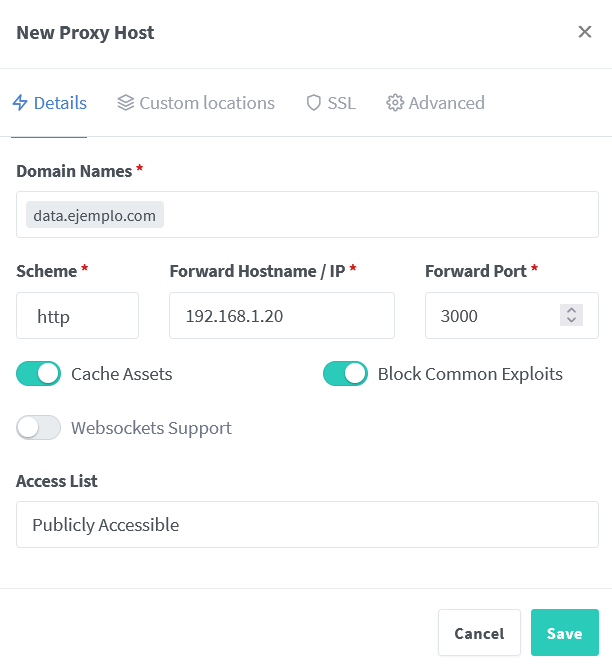
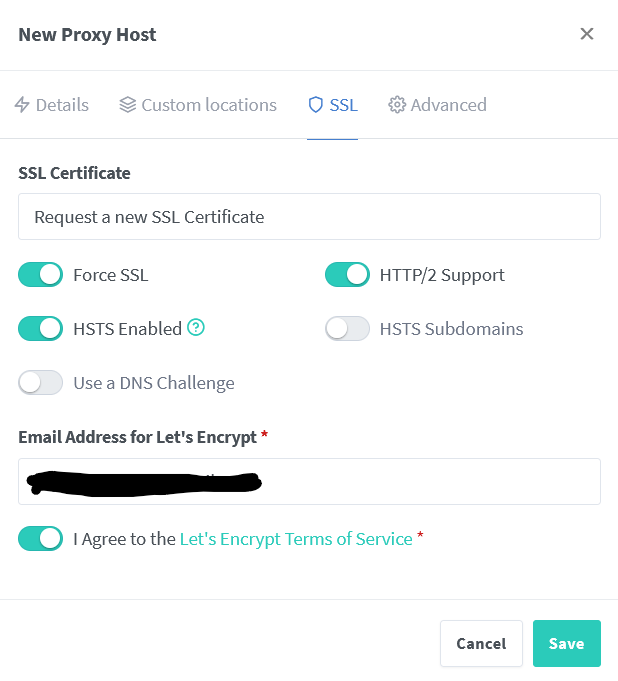
Ahora, una vez creado el servicio, tenemos que dar un paso en medio para que Grafana funcione correctamente al acceder desde el exterior. Vamos a editar la configuración del contenedor de grafana, y dentro, le damos a Add another Path, Port, Variable, Label or Device y creamos una variable con la URL que acabamos de crear en Nginx:
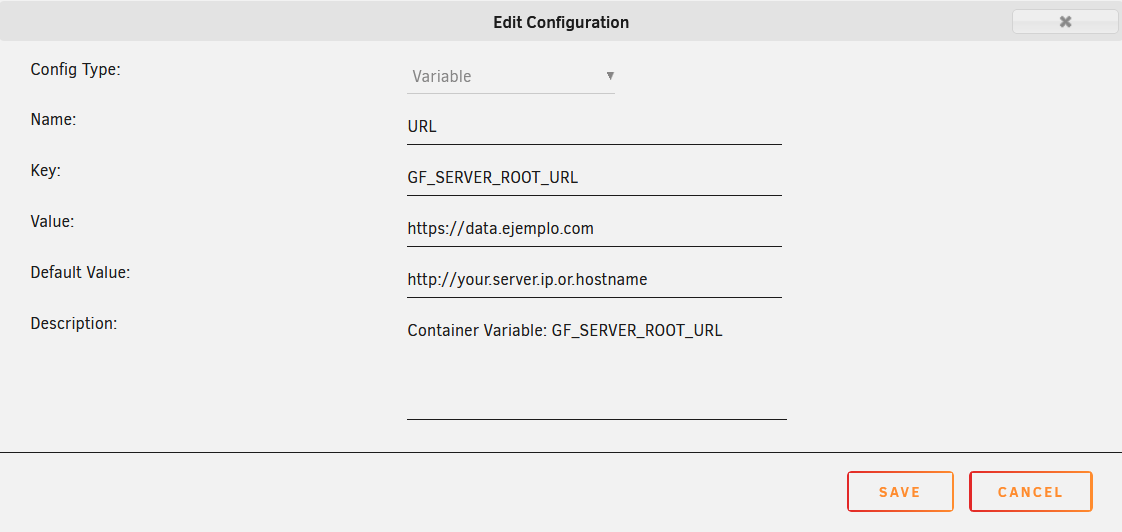
Guardamos y aplicamos. Ahora, si accedemos desde la URL creada debería de aparecernos la pantalla de login de Grafana.
Dashboards embebidos en Home Assistant
Una de las cosas que podemos hacer en nuestro centro domótico es incrustar, mediante iframes, otros servicios web ajenos al propio Home Assistant. Esto es muy útil si queremos acceder a todo desde una sola URL y pestaña de navegador (y aplicación móvil, si usamos la app nativa de Hass).
Para que este iframe nos quede aún mejor, Grafana tiene la opción de visualizar los dashboard en modo Kiosko escondiendo toda la interfaz salvo los paneles. Para obtener la URL del modo kiosko vamos a nuestro dashboard de Grafana y arriba a la derecha hacemos click en el icono de la pantalla. Si haces click dos veces verás que solo quedan los paneles a la vista:
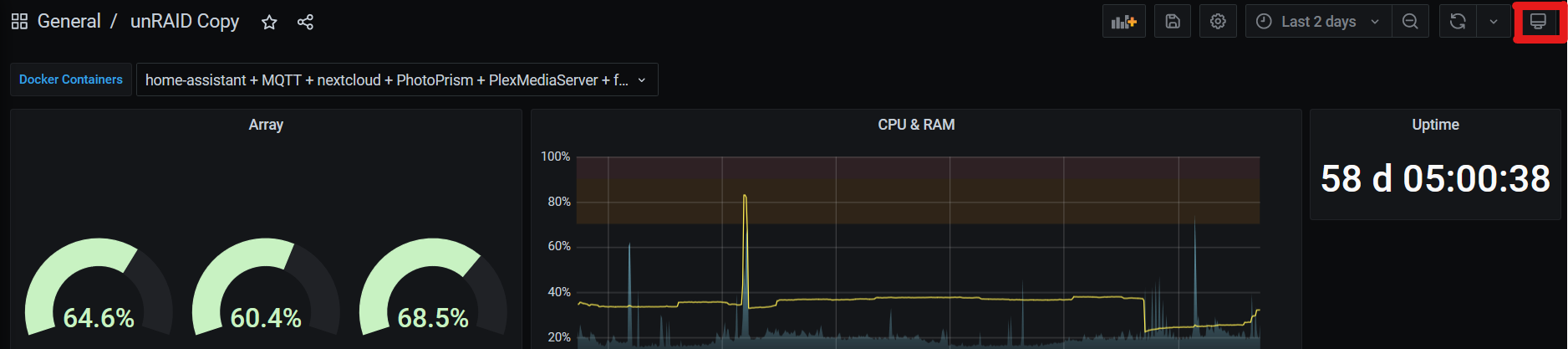
Para embeber el dashboard dentro de grafana, lo tendremos que hacer modificando el archivo principal de configuración que tendremos en la ruta/share \ip-de-UnRaid\appdata\Home-Assistant-Core\configuration.yaml
Abrimos este archivo con nuestro editor de código añadimos lo siguiente:
panel_iframe:
unraid:
title: "Unraid"
url: "URL-de-grafana-kiosko"
icon: mdi:server
require_admin: true # Solo si queremos que lo vean los usuarios admin de HassGuardamos el archivo y reiniciamos el servidor. Ya debería aparecer el icono de un servidor en la parte izquierda de tu Home Assistant:
Ahora ya queda en tus manos empezar a jugar con las opciones que tiene Grafana para hacer visualizaciones y dejar las cosas a tu gusto. En el siguiente post, vamos a sensorizar nuestras plantas y conectando Home Assistant e InfluxDB, vamos a monitorizarlas con Grafana para que ellas mismas nos pidan que las reguemos cuando les haga falta.
Si tienes cualquier duda no dudes en dejarlo en los comentarios y te ayudaré en lo que pueda.
Nota: algunos de los enlaces a productos o servicios pueden ser enlaces referidos con los que podemos obtener una comisión de venta.